
变量是偷偷摸摸的。有时,它们会很高兴地呆在寄存器中,但是一转头就会跑到堆栈中。为了优化,编译器可能会完全将它们从窗口中抛出。无论变量在内存中的如何移动,我们都需要一些方法在调试器中跟踪和操作它们。这篇文章将会教你如何处理调试器中的变量,并使用 libelfin 演示一个简单的实现。
系列文章索引
准备环境(http://www.linuxdiyf.com/linux/31643.html)
断点(http://www.linuxdiyf.com/linux/31737.html)
寄存器和内存(http://www.linuxdiyf.com/linux/31847.html)
源码和信号(http://www.linuxdiyf.com/linux/32098.html)
源码级逐步执行(http://www.linuxdiyf.com/linux/32424.html)
源码级断点(http://www.linuxdiyf.com/linux/32650.html)
堆栈展开(http://www.linuxdiyf.com/linux/32724.html)
处理变量
高级话题
在开始之前,请确保你使用的 libelfin 版本是我分支上的 fbreg。这包含了一些 hack 来支持获取当前堆栈帧的基址并评估位置列表,这些都不是由原生的 libelfin 提供的。你可能需要给 GCC 传递 -gdwarf-2 参数使其生成兼容的 DWARF 信息。但是在实现之前,我将详细说明 DWARF 5 最新规范中的位置编码方式。如果你想要了解更多信息,那么你可以从 http://dwarfstd.org/ 获取该标准。
DWARF 位置
某一给定时刻的内存中变量的位置使用 DW_AT_location 属性编码在 DWARF 信息中。位置描述可以是单个位置描述、复合位置描述或位置列表。
简单位置描述:描述了对象的一个连续的部分(通常是所有部分)的位置。简单位置描述可以描述可寻址存储器或寄存器中的位置,或缺少位置(具有或不具有已知值)。比如,DW_OP_fbreg -32: 一个整个存储的变量 - 从堆栈帧基址开始的32个字节。
复合位置描述:根据片段描述对象,每个对象可以包含在寄存器的一部分中或存储在与其他片段无关的存储器位置中。比如, DW_OP_reg3 DW_OP_piece 4 DW_OP_reg10 DW_OP_piece 2:前四个字节位于寄存器 3 中,后两个字节位于寄存器 10 中的一个变量。
位置列表:描述了具有有限生存期或在生存期内更改位置的对象。比如:
<loclist with 3 entries follows>
[ 0]<lowpc=0x2e00><highpc=0x2e19>DW_OP_reg0
[ 1]<lowpc=0x2e19><highpc=0x2e3f>DW_OP_reg3
[ 2]<lowpc=0x2ec4><highpc=0x2ec7>DW_OP_reg2
根据程序计数器的当前值,位置在寄存器之间移动的变量。
根据位置描述的种类,DW_AT_location 以三种不同的方式进行编码。exprloc 编码简单和复合的位置描述。它们由一个字节长度组成,后跟一个 DWARF 表达式或位置描述。loclist 和 loclistptr 的编码位置列表,它们在 .debug_loclists 部分中提供索引或偏移量,该部分描述了实际的位置列表。
DWARF 表达式
使用 DWARF 表达式计算变量的实际位置。这包括操作堆栈值的一系列操作。有很多 DWARF 操作可用,所以我不会详细解释它们。相反,我会从每一个表达式中给出一些例子,给你一个可用的东西。另外,不要害怕这些;libelfin 将为我们处理所有这些复杂性。
字面编码
DW_OP_lit0、DW_OP_lit1……DW_OP_lit31
将字面量压入堆栈
DW_OP_addr <addr>
将地址操作数压入堆栈
DW_OP_constu <unsigned>
将无符号值压入堆栈
寄存器值
DW_OP_fbreg <offset>
压入在堆栈帧基址找到的值,偏移给定值
DW_OP_breg0、DW_OP_breg1…… DW_OP_breg31 <offset>
将给定寄存器的内容加上给定的偏移量压入堆栈
堆栈操作
DW_OP_dup
复制堆栈顶部的值
DW_OP_deref
将堆栈顶部视为内存地址,并将其替换为该地址的内容
算术和逻辑运算
DW_OP_and
弹出堆栈顶部的两个值,并压回它们的逻辑 AND
DW_OP_plus
与 DW_OP_and 相同,但是会添加值
控制流操作
DW_OP_le、DW_OP_eq、DW_OP_gt 等
弹出前两个值,比较它们,并且如果条件为真,则压入 1,否则为 0
DW_OP_bra <offset>
条件分支:如果堆栈的顶部不是 0,则通过 offset 在表达式中向后或向后跳过
输入转化
DW_OP_convert <DIE offset>
将堆栈顶部的值转换为不同的类型,它由给定偏移量的 DWARF 信息条目描述
特殊操作
DW_OP_nop
什么都不做!
DWARF 类型
DWARF 类型的表示需要足够强大来为调试器用户提供有用的变量表示。用户经常希望能够在应用程序级别进行调试,而不是在机器级别进行调试,并且他们需要了解他们的变量正在做什么。
DWARF 类型与大多数其他调试信息一起编码在 DIE 中。它们可以具有指示其名称、编码、大小、字节等的属性。无数的类型标签可用于表示指针、数组、结构体、typedef 以及 C 或 C++ 程序中可以看到的任何其他内容。
以这个简单的结构体为例:
struct test{
int i;
float j;
int k[42];
test* next;
};
这个结构体的父 DIE 是这样的:
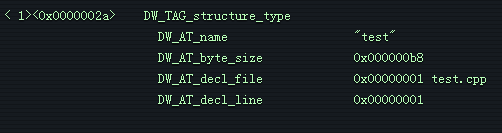
上面说的是我们有一个叫做 test 的结构体,大小为 0xb8,在 test.cpp 的第 1 行声明。接下来有许多描述成员的子 DIE。
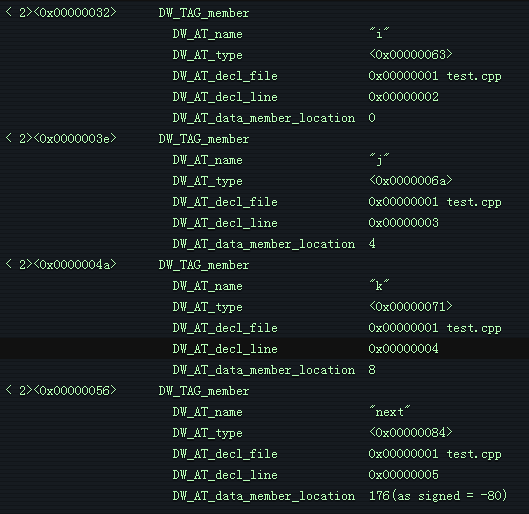
每个成员都有一个名称、一个类型(它是一个 DIE 偏移量)、一个声明文件和行,以及一个指向其成员所在的结构体的字节偏移。其类型指向如下。
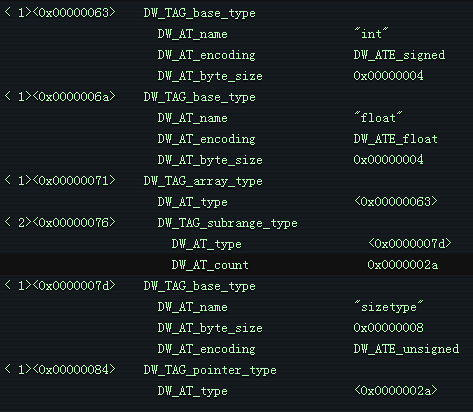
如你所见,我笔记本电脑上的 int 是一个 4 字节的有符号整数类型,float是一个 4 字节的浮点数。整数数组类型通过指向 int 类型作为其元素类型,sizetype(可以认为是 size_t)作为索引类型,它具有 2a 个元素。 test * 类型是 DW_TAG_pointer_type,它引用 test DIE。
实现简单的变量读取器
如上所述,libelfin 将为我们处理大部分复杂性。但是,它并没有实现用于表示可变位置的所有方法,并且在我们的代码中处理这些将变得非常复杂。因此,我现在选择只支持 exprloc。请根据需要添加对更多类型表达式的支持。如果你真的有勇气,请提交补丁到 libelfin 中来帮助完成必要的支持!
处理变量主要是将不同部分定位在存储器或寄存器中,读取或写入与之前一样。为了简单起见,我只会告诉你如何实现读取。
首先我们需要告诉 libelfin 如何从我们的进程中读取寄存器。我们创建一个继承自 expr_context 的类并使用 ptrace 来处理所有内容:
class ptrace_expr_context : public dwarf::expr_context {
public:
ptrace_expr_context (pid_t pid) : m_pid{pid} {}
dwarf::taddr reg (unsigned regnum) override {
return get_register_value_from_dwarf_register(m_pid, regnum);
}
dwarf::taddr pc() override {
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, m_pid, nullptr, ®s);
return regs.rip;
}
dwarf::taddr deref_size (dwarf::taddr address, unsigned size) override {
//TODO take into account size
return ptrace(PTRACE_PEEKDATA, m_pid, address, nullptr);
}
private:
pid_t m_pid;
};
读取将由我们 debugger 类中的 read_variables 函数处理:
void debugger::read_variables() {
using namespace dwarf;
auto func = get_function_from_pc(get_pc());
//...
}
我们上面做的第一件事是找到我们目前进入的函数,然后我们需要循环访问该函数中的条目来寻找变量:
for (const auto& die : func) {
if (die.tag == DW_TAG::variable) {
//...
}
}
我们通过查找 DIE 中的 DW_AT_location 条目获取位置信息:
auto loc_val = die[DW_AT::location];
接着我们确保它是一个 exprloc,并请求 libelfin 来评估我们的表达式:
if (loc_val.get_type() == value::type::exprloc) {
ptrace_expr_context context {m_pid};
auto result = loc_val.as_exprloc().evaluate(&context);
现在我们已经评估了表达式,我们需要读取变量的内容。它可以在内存或寄存器中,因此我们将处理这两种情况:
switch (result.location_type) {
case expr_result::type::address:
{
auto value = read_memory(result.value);
std::cout << at_name(die) << " (0x" << std::hex << result.value << ") = "
<< value << std::endl;
break;
}
case expr_result::type::reg:
{
auto value = get_register_value_from_dwarf_register(m_pid, result.value);
std::cout << at_name(die) << " (reg " << result.value << ") = "
<< value << std::endl;
break;
}
default:
throw std::runtime_error{"Unhandled variable location"};
}
你可以看到,我根据变量的类型,打印输出了值而没有解释。希望通过这个代码,你可以看到如何支持编写变量,或者用给定的名字搜索变量。
最后我们可以将它添加到我们的命令解析器中:
else if(is_prefix(command, "variables")) {
read_variables();
}
测试一下
编写一些具有一些变量的小功能,不用优化并带有调试信息编译它,然后查看是否可以读取变量的值。尝试写入存储变量的内存地址,并查看程序改变的行为。
已经有九篇文章了,还剩最后一篇!下一次我会讨论一些你可能会感兴趣的更高级的概念。现在你可以在 https://github.com/TartanLlama/minidbg/tree/tut_variable 找到这个帖子的代码。