我打算在虚拟机中同时开启3台机器,实现分布式的Hadoop群集。
1.准备3台Ubuntu Server
1.1.复制出3台虚拟机
我们可以用之前编译和安装好Hadoop的虚拟机作为原始版本,在VirtualBox中复制三台新的虚拟机出来,也可以完全重新安装一台全新的Ubuntu Server,然后在VirtualBox中复制出2台,就变成了3台虚拟机。
1.2.修改主机名
主机名保存在/etc/hostname文件中,我们可以运行
sudo vi /etc/hostname
命令,然后为三台机器起不同的名字,这里我们就分别起名:
master
slave01
slave02
1.3.修改为固定IP
Ubuntu的IP地址保存到/etc/network/interfaces文件中,我们需要为3台虚拟机分别改为固定的IP,这里我的环境是在192.168.100.*网段,所以我打算为master改为192.168.100.40,操作如下:
sudo vi /etc/network/interfaces
然后可以看到每个网卡的配置,我这里网卡名是叫enp0s3,所以我改对应的内容为:
# The primary network interface
auto enp0s3
iface enp0s3 inet static
address 192.168.100.40
gateway 192.168.100.1
netmask 255.255.255.0
对slave01改为192.168.100.41,slave02改为192.168.100.42。
1.4.修改Hosts
由于三台虚拟机是使用的默认的DNS,所以我们需要增加hosts记录,才能直接用名字相互访问。hosts文件和Windows的Hosts文件一样,就是一个域名和ip的对应表。
编辑hosts文件:
sudo vi /etc/hosts
增加三条记录:
192.168.100.40 master
192.168.100.41 slave01
192.168.100.42 slave02
1.5.重启
这一切修改完毕后我们重启一下三台机器,然后可以试着各自ping master,ping slave01 ping slave02看能不能通。按照上面的几步操作,应该是没有问题的。
1.6.新建用户和组
这一步不是必须的,就采用安装系统后的默认用户也是可以的。
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
为了方便,我们还可以把hduser添加到sudo这个group中,那么以后我们在hduser下就可以运行sudo xxx了。
sudo adduser hduser sudo
切换到hduser:
su – hduser
1.7.配置无密码访问SSH
在三台机器上首先安装好SSH
sudo apt-get install ssh
然后运行
ssh-keygen
默认路径,无密码,会在当前用户的文件夹中产生一个.ssh文件夹。
接下来我们先处理master这台机器的访问。我们进入这个文件夹,
cd .ssh
然后允许无密码访问,执行:
cp id_rsa.pub authorized_keys
然后要把slave01和slave02的公钥传给master,进入slave01
scp ~/.ssh/id_rsa.pub hduser@master:/home/hduser/.ssh/id_rsa.pub.slave01
然后在slave02上也是:
scp ~/.ssh/id_rsa.pub hduser@master:/home/hduser/.ssh/id_rsa.pub.slave02
将 slave01 和 slave02的公钥信息追加到 master 的 authorized_keys文件中,切换到master机器上,执行:
cat id_rsa.pub.slave01 >> authorized_keys
cat id_rsa.pub.slave02 >> authorized_keys
现在authorized_keys就有3台机器的公钥,可以无密码访问任意机器。只需要将authorized_keys复制到slave01和slave02即可。在master上执行:
scp authorized_keys hduser@slave01:/home/hduser/.ssh/authorized_keys
scp authorized_keys hduser@slave02:/home/hduser/.ssh/authorized_keys
最后我们可以测试一下,在master上运行
ssh slave01
如果没有提示输入用户名密码,而是直接进入,就说明我们配置成功了。
同样的方式测试其他机器的无密码ssh访问。
2.安装相关软件和环境
如果是直接基于我们上一次安装的单机Hadoop做的虚拟机,那么这一步就可以跳过了,如果是全新的虚拟机,那么就需要做如下操作:
2.1.配置apt source,安装JDK
sudo vi /etc/apt/sources.list
打开后把里面的us改为cn,如果已经是cn的,就不用再改了。然后运行:
sudo apt-get update
sudo apt-get install default-jdk
2.2.下载并解压Hadoop
去Hadoop官网,找到最新稳定版的Hadoop下载地址,然后下载。当然如果是X64的Ubuntu,我建议还是本地编译Hadoop,具体编译过程参见这篇文章。
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
下载完毕后然后是解压
tar xvzf hadoop-2.7.3.tar.gz
最后将解压后的Hadoop转移到正式的目录下,这里我们打算使用/usr/local/hadoop目录,所以运行命令:
sudo mv hadoop-2.7.3 /usr/local/hadoop
3.配置Hadoop
3.1.配置环境变量
编辑.bashrc或者/etc/profile文件,增加如下内容:
# Java Env
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
# Hadoop Env
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.2.进入Hadoop的配置文件夹:
cd /usr/local/hadoop/etc/hadoop
(1)修改hadoop-env.sh
增加如下配置:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_PREFIX=/usr/local/hadoop
(2)修改core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/temp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
这里我们指定了一个临时文件夹的路径,这个路径必须存在,而且有权限访问,所以我们在hduser下创建一个temp目录。
(3)hdfs-site.xml
设置HDFS复制的数量
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(4)mapred-site.xml
这里可以设置MapReduce的框架是YARN:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)配置YARN环境变量,打开yarn-env.sh
里面有很多行,找到JAVA_HOME,设置:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
(6)配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
(7)最后打开slaves文件,设置有哪些slave节点。
由于我们设置了3份备份,把master即是Name Node又是Data Node,所以我们需要设置三行:
master
slave01
slave02
3.3.配置slave01和slave02
在slave01和slave02上做前面3.1 3.2相同的设置。
一模一样的配置,这里不再累述。
4.启动Hadoop
回到Master节点,我们需要先运行
hdfs namenode –format
格式化NameNode。
然后执行
start-all.sh
这里Master会启动自己的服务,同时也会启动slave01和slave02上的对应服务。
启动完毕后我们在master上运行jps看看有哪些进程,这是我运行的结果:
2194 SecondaryNameNode
2021 DataNode
1879 NameNode
3656 Jps
2396 ResourceManager
2541 NodeManager
切换到slave01,运行jps,可以看到如下结果:
1897 NodeManager
2444 Jps
1790 DataNode
切换到slave02也是一样的有这些服务。
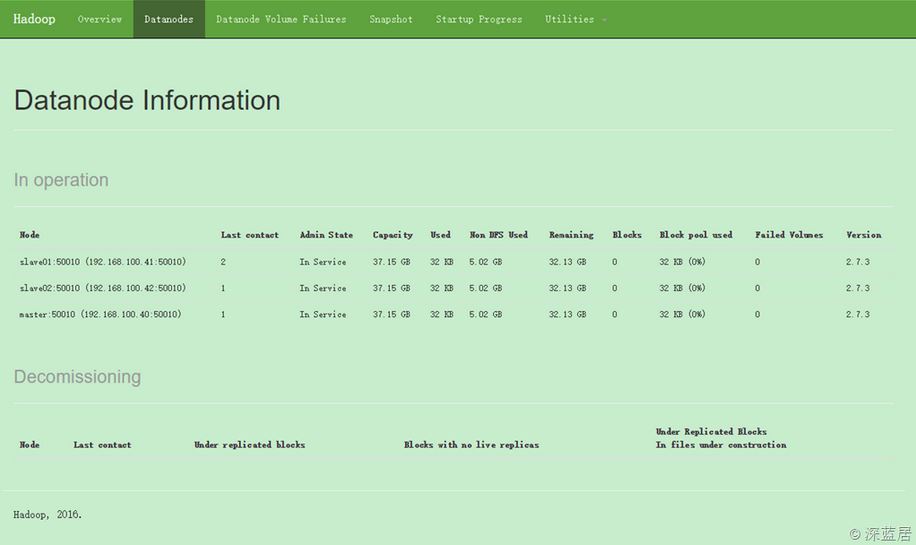
那么说明我们的服务网都已经启动成功了。
现在我们在浏览器中访问:
http://192.168.100.40:50070/
应该可以看到Hadoop服务已经启动,切换到Datanodes可以看到我们启动的3台数据节点: