
之前在windows下搭建了一个spark的开发环境,但是后来发现如果想要搞spark streaming的例子的话在Linux下使用更方便,于是在centos7下面搭建一下spark开发环境,记录以做备忘之用。
1.首先去spark官网下载相关软件,我这里用的是spark2.1.0版本http://spark.apache.org/downloads.html,对应的hadoop版本是2.7.0
2.

3.之后利用XSheel5将下载的压缩包传递到linux的主节点的opt目录下,这里我的主节点的ip为192.168.70.100

4.之后切换到opt目录下,用tar -zxvf命令进行解压缩,解压缩后得到去掉后缀的文件夹
5.之后进入 vim /etc/profile,修改配置文件,添加spark的相关内容,见下图,之后退出用source /etc/profile进行保存

6.接下来修改之前解压缩目录下的conf下的spark-env.sh文件,通过cp命令复制一下模板

7.之后通过vim 进入,在末尾添加这些东西见下图,最后一个是主节点的ip地址,根据实际情况改成自己的

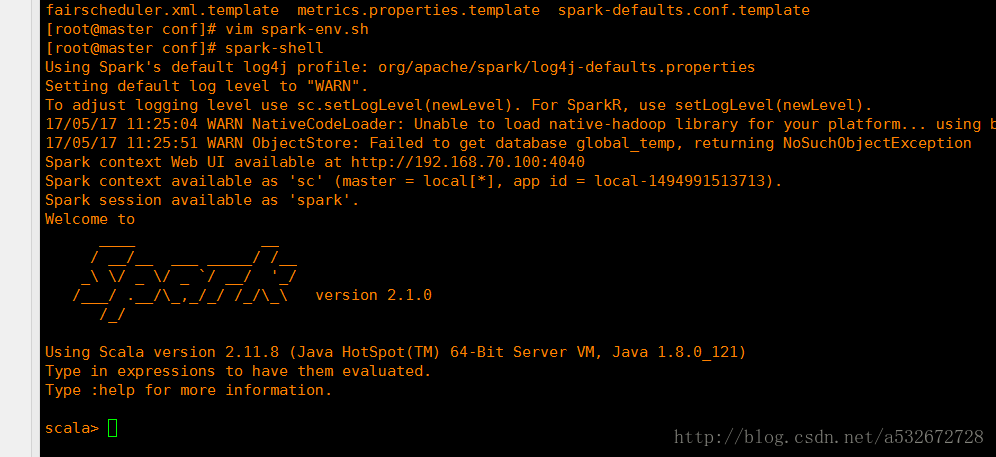
8.在这之前先在任何一个位置输入spark-shell,测试一下环境变量是否配置成功,如果出现下面这个图表明成功
9.接下来修改spark下的conf下面的slaves文件,添加子节点的ip地址,如果这里没有这个文件,可以通过cp 命令进行复制slaves模板得到,我这里有三个子节点,根据自己的实际情况进行修改即可
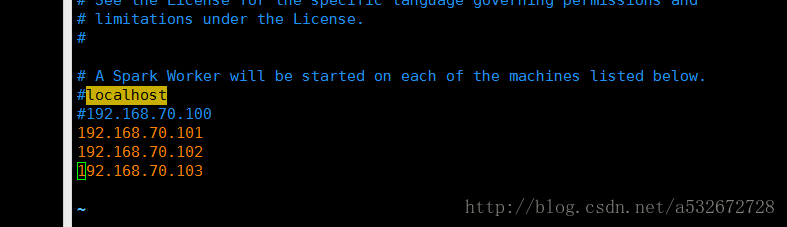
10.将上面这个保存,到此主节点的spark的相关配置已经完成,接下来只需要将该配置分发到其他子节点即可,之前已经配置了免密登录,如果这里有问题,可以参考免密登录的相关内容,我这里有三个子节点,全部拷贝到相同目录下即可

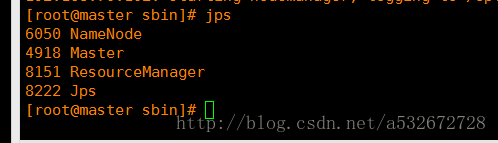
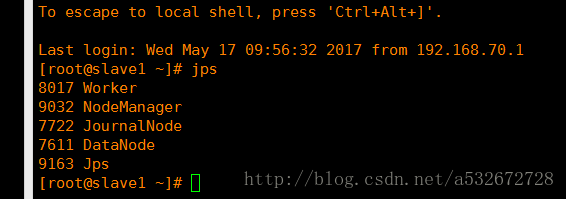
11.之后先启动hadoop,分别调用start-dfs.sh和start-yarn.sh,之后进入spark的sbin目录启动start-master.sh和start-slaves.sh,启动完毕后在主节点和子节点分别调用jps查看进程如下图
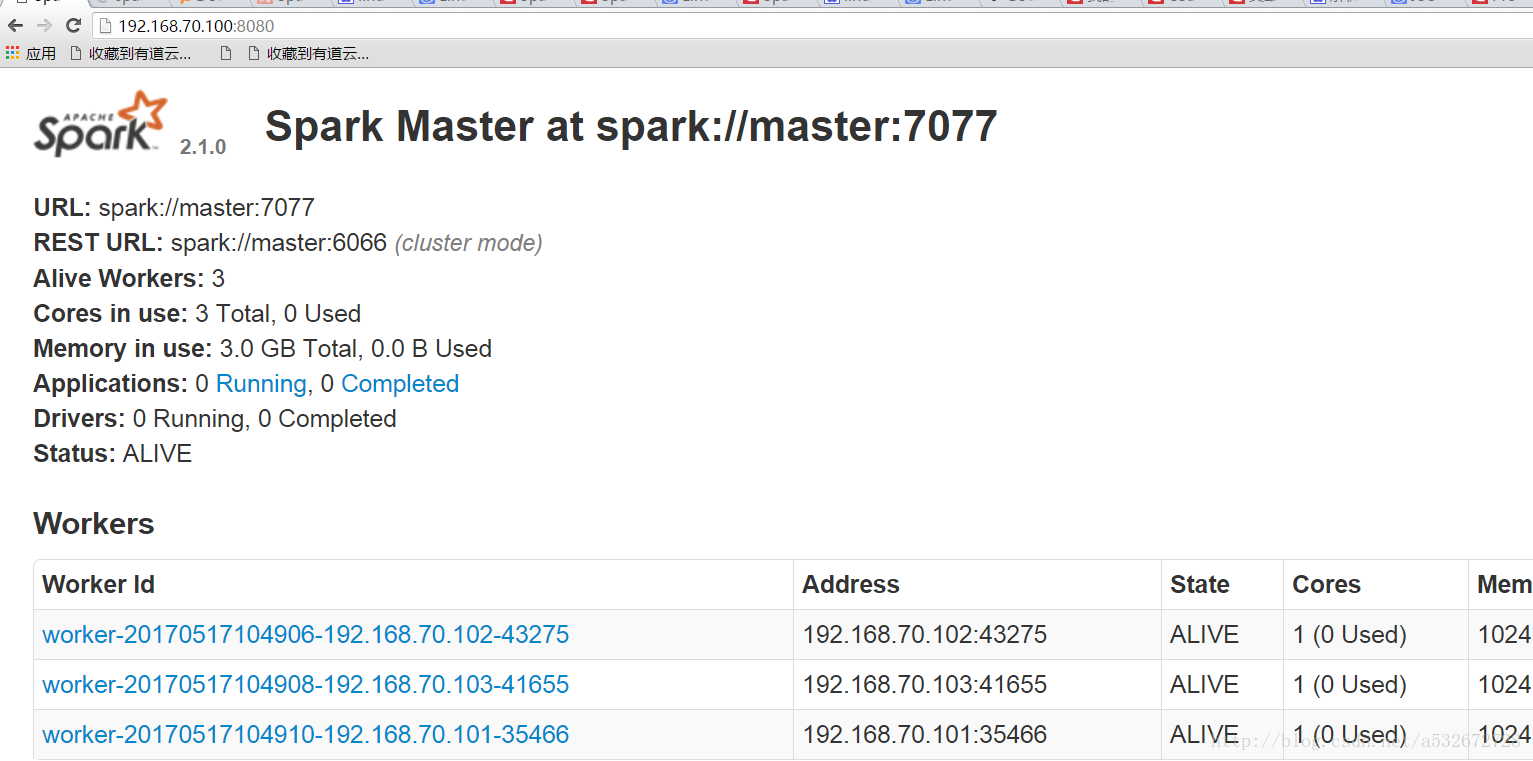
12.之后登录8080查看spark的管理界面,出现下图说明集群搭建成功暂时告一段落,这里根据自己的主节点的ip地址进行修改即可。
13.接下里就可以进行实操了。