
1.前言:
之前对编译安装tf做了很多的工作,遇到了许多问题也解决了(如:sudo init 3准备关掉x server 时黑屏,解决方案是对/etc/default/grub编辑,在显示那一条后面加上nomodeset,然后sudo upgrade-grub,然后重启机器,分辨率下降,sudo init 3,alt+ctrl+f1进入tty登录,sudo service lightdm stop关掉,然后安装即可,安装完重启x server,sudo service lilghtdm restart,并且讲grub修改回原来样子,再重启机器...等等,类似的问题中文论坛没几篇相关文章,浪费了大量时间)。
(在这里讲一下编译安装和预编译安装的区别:编译安装需要Google自家的bazel编译软件及gcc通过下载tf源码,对.configure进行配置,各种配置要求可以按咱们需要配置,配置好后bazel编译,再生成pip安装包,再pip安装;预编译是直接到tf上下载预编译好的pip安装包,pip安装,这样的安装容易出现的问题是可能不会和cuda、cudnn很好的匹配,可能会出现不兼容的问题)
但是在导入tf包时会跳出问题。所以为了节省时间,接下来采用deb安装cuda、pip安装tf的方式安装gpu加速版tf,等以后如果出现配置不兼容的问题再花时间重新编译安装吧。
2.安装tf
安装好ubuntu系统后,在系统设置-软件与更新-驱动,选择nvidia的最新驱动。
2.1.安装anaconda
然后在安装tf之前首先要安装python环境,这里推荐安装anaconda3,4.2.0版,3.5.2的python。
然后bash anaconda的.sh文件安装,记得一定要讲binary路径加入到~/.bashrc文件中(环境变量)。
可以使用python指令看看安装好没有。

这样就是安装好了,后面提示是anaconda提供的python环境。
2.2.安装cuda及cudnn
接下来是cuda和cudnn库的安装和配置。
到这里https://developer.nvidia.com/cuda-downloads下载cuda的deb版安装包。

按照上图官网给出的安装指示进行安装。
到这里https://developer.nvidia.com/cudnn下载cudnn库,需要注册账号,随便注册一个。
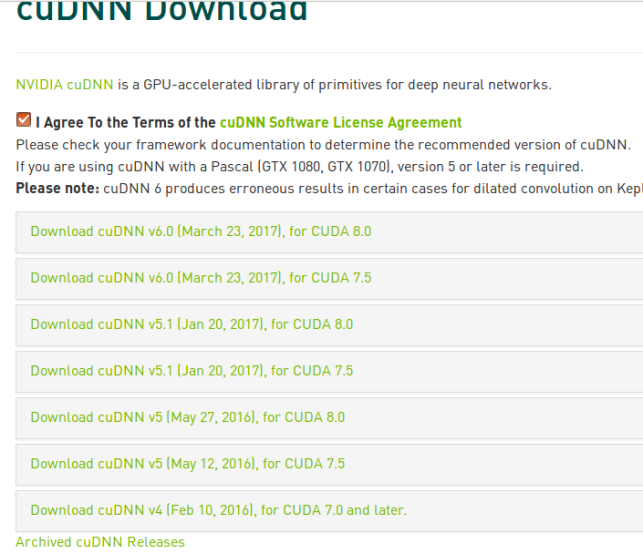
我们选择支持8.0cuda 的5.1版本,因为6.0版本算是个测试版,经常会出问题,所以选择了5.1。
如下图所示两个包已经下载好。
接下来安装cudnn,进入cuda所在的安装路径
cd /usr/local
sudo tar -zxvf ~/downloads/cudnn-8.0-linux-x64-v5.1.tgz
(一个小技巧,写到某个目录时如果文件名过长,输入几个提示字母按tab可迅速补全)
完成了cudnn的安装,但是还要配置环境变量里的cuda 的路径。
vim ~/.bashrc
export LD_LIBRARY_PATH="/usr/local/cuda-8.0/lib64:/usr/local/cuda-
8.0/extras/CUPTI/lib64:$LD_LIBRARY_PATH"
export CUDA_HOME="/usr/local/cuda-8.0"
export PATH="/usr/local/cuda-8.0/bin:$PATH"
最后 source ~/.bashrc 使配置生效。
2.3.安装tf
接下来使用预编译的包安装tf。

pip版本可能不是最新所以需要更新。

更新后安装。

可能会遇到这个问题。

使用如下指令解决。

再使用安装命令即可安装成功
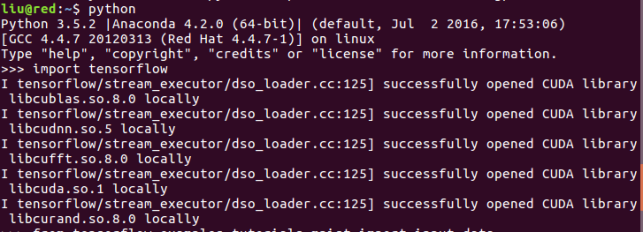
如图显示即为导入包成功、安装成功。
3.mnist小实验(tf快速入门)
接下来进行一个tf中的hello world的任务进行入门实验。
mnist是一个cv的数据集,包含几万张28x28像素的手写体数字组成,像素只包含灰度信息。我们
的任务是对这些图片进行分类0~9一共10类。
接下来读取数据集,保存在MNIST_data文件夹中。
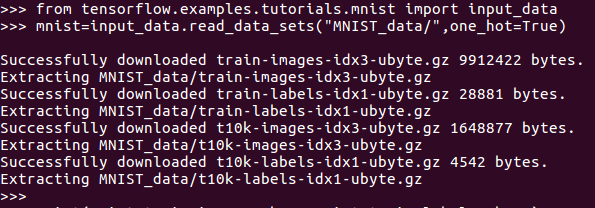
这里可能因为在线下载的原因,速度较慢等了一会儿。
通过查看数据集,我们可以知道,训练集有55000个样本,测试集有10000个样本,验证集有5000个样本,每个样本集的标注label为10类,以one-hot方式编码。

创建一个新的interactivesession。

从返回的信息来看,前四条不用担忧(意思是tflib没有编译sse4.2、AVX、AVX2、FMA但是这些我的机器上都有,所以可以用来加速cpu计算),第五条num node相关的知识可以搜索一下,如果大量占用内存的话,推荐不使用num node,如果小规模占用内存,快速访问则使用num node,一开始=-1应该是没有用到,因为这里的tf默认至少使用一个num node,所以令num node=1,如果多cpu架构再考虑这个问题,第六条显示的是本地的gpu信息。

接下来使用一层网络节点,输出直接softmax,placeholder是输入。可以看到,输入是tensor张量,一旦用完就会消失,w、b是variable在模型中是持久化的,w、b初始化为0。softmax是tf.nn的一个函数,tf.nn包含了大量的nn组件,tf.matmul是tf中的矩阵乘法函数。tf最厉害的地方是forward和backward都可以自动实现。所以我们接下来的任务是定义好loss。

我们定义loss为cross-entropy。y_为输出,reduce_sum是求和,reduce_mean是求每个batch的均值。
接下来调用SGD随机梯度下降进行优化。学习率为0.1,反向传播为cross_entropy

下一步使用tf的全局参数初始化器初始化。

接下来我们开始迭代的执行训练操作train_step,并且每次从训练集中抽取100条样本做mini-batch,并feed给placeholder,然后调用train_step训练。

输入代码时注意缩进。现在我们已经完成了训练,一秒不到的时间。
接下来对模型的准确率进行验证。
tf.argmax(y,1)是找y中最大值的那个序号,tf.equal()是判断预测类别是否正确,correct_prediction是bool类型。
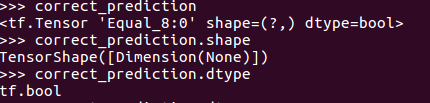
tf.cast是讲预测输出的bool值转化为float32,tf.reduce_mean再求平均,联系计算公式可以想出这么做的原因。
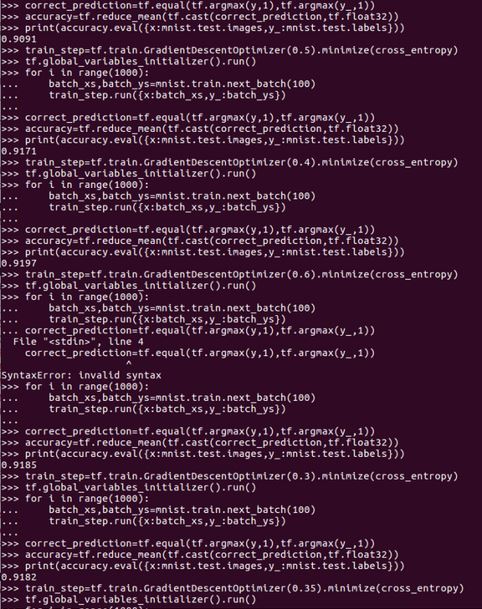
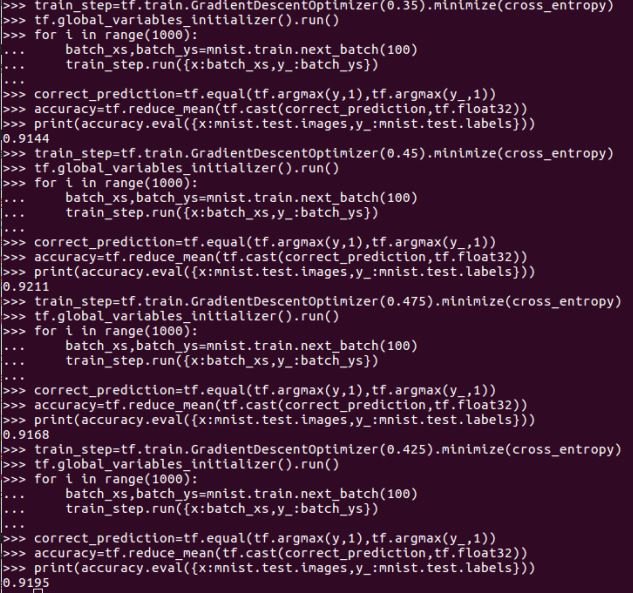
通过对不同学习率的选择,我们能明显感觉到学习率对于结果的影响,目前学习率取0.45效果最好。准确率能达到92%左右。