
在cloudstack4.5.2版本下,偶尔出现libvirtd服务无响应的情况,导致virsh命令无法使用,同时伴随cloudstack master丢失该slave主机连接的情况。最初怀疑是libvirtd服务或版本的问题,经过分析和排查最终确定是cloudstack-agent的问题。但是在官网上并没有找到类似的bug提交,该问题可能还存在于更高的版本,需要时间进一步从根本上分析。下面是该问题的处理过程,在此记录下,关注和使用cloudstack的朋友可以参考。
众所周知,cloudstack的社区热度远不如openstack,为什么还要选择clcoudstack?这个问题以后有机会再和大家聊。言归正传。
环境交代
宿主机操作系统:centos6.5x64(2.6.32-431.el6.x86_64)
cloudstack版本:4.5.2
libvirt版本:libvirt-0.10.2-54.el6_7.2.x86_64
问题描述
通过cloudstackapi listHosts报警信息显示:
node5.cloud.rtmap:192.168.14.20 state is Down at 2016-05-13T07:19:04+0800
#有关cloudstackapi的使用方法在其它文章中总结,不在此处说明。
登陆问题宿主服务器检查:
[root@node5 log]#virsh list --all
没有响应ctrl^c退出
这时的vm可以正常工作,但处于失控状态
尝试重启启动libvirtd服务:
[root@node5 log]# service libvirtd stop
正在关闭 libvirtd 守护进程: [失败] #无法关闭libvirtd服务
尝试重启启动cloudstack-agent服务:
[root@node5 libvirt]# service cloudstack-agent restart
Stopping Cloud Agent:
Starting Cloud Agent:
libvirtd故障依旧
简单维护
[root@node5 ping]# libvirtd -d -l --config /etc/libvirt/libvirtd.conf
libvirtd:错误:Unable to initialize network sockets。查看 /var/log/messages 或者运行不带 --daemon 的命令查看更多信息。
[root@node5 log]# libvirtd -d
可以执行成功,这时执行virsh list --all 可以查看和操作vm
[root@node5 log]#virsh list --all
Id 名称 状态
----------------------------------------------------
2 i-4-185-VM running
虽然vm运行正常,现在也可以通过命令正常管理了。但是对于cloudstack平台而言,宿主机处于down状态,vm处于失控状态。
临时解决办法是在其它大的升级和维护过程中重启服务器解决,根本解决还要具体问题具体分析。
分析与排查
检查进程

杀进程
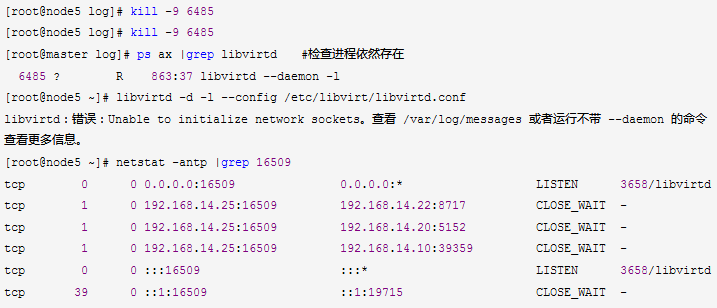
经过上述操作,初步判断libvirtd陷入了hang死状态。
追踪进程

父进程6485在不断的产生和关闭子进程,并返回错误信息。Bad file descriptor的原因(如何触发的,谁触发的)?循环为何无法退出?问题如何再现?
获得更多的线索
官方文档(libvirtd各种故障诊断记录和解决办法非常详尽)
开启系统日志
Change libvirt's logging in /etc/libvirt/libvirtd.conf by enabling the line below. To enable the setting the line, open the /etc/libvirt/libvirtd.conf file in a text editor, remove the hash (or #) symbol from the beginning of the following line, and save the change:
log_outputs="3:syslog:libvirtd"
参照配置,重启服务器等待下次故障观察日志

并未获得致命错误和更多线索。(该日志配置选项还是很有必要打开的,很多问题都可以通过它来定位)
解决过程
解决思路
尝试和找到终止进程、重启服务的方法
提交bug,等待补丁升级
分析源代码,再现问题,解决问题(投入研发和时间)
由于不能再现问题,还是从简入繁吧。触发这些子进程的元凶是谁?还是cloudstack-agent的嫌疑最大,但之前重启过该服务并没有解决问题,那么agent服务是怎么一回事呢?
看下启动脚本可以基本了解,
[root@node5 libvirt]# cat /etc/rc.d/init.d/cloudstack-agent

[root@node5 libvirt]# ps ax |grep jsvc.exec

重启服务
[root@node5 bin]# service cloudstack-agent status
cloudstack-agent (pid 6657) 正在运行...
[root@node5 bin]# service cloudstack-agent stop
Stopping Cloud Agent:
[root@node5 bin]# service cloudstack-agent status
cloudstack-agent (pid 6657) 正在运行..
ps ax |grep jsvc.exec 也验证了进程依然存在
眼前一亮的同时,也发现了之前使用restart带来的问题,stop不成功的问题被掩盖了~~~有没有懊恼? 不过来不及反思,接下来的问题还远不是这么简单......
[root@node5 bin]# kill -9 6655 6657
[root@node5 bin]# kill -9 6655 6657
-bash: kill: (6655) - 没有那个进程
-bash: kill: (6657) - 没有那个进程
[root@node5 bin]# service cloudstack-agent status
cloudstack-agent 已死,但 pid 文件仍存
[root@node5 bin]# rm /var/run/cloudstack-agent.pid
rm:是否删除普通文件 "/var/run/cloudstack-agent.pid"?y
[root@node5 bin]# service cloudstack-agent status
cloudstack-agent 已死,但是 subsys 被锁
[root@node5 bin]# service cloudstack-agent start
[root@node5 bin]# service cloudstack-agent status
cloudstack-agent (pid 109382) 正在运行...
[root@node5 bin]# netstat -antp |grep 8250
tcp 0 0 192.168.14.20:22220 192.168.14.10:8250 ESTABLISHED 109382/jsvc.exec
处理后状态恢复正常,但是libvirtd仍然无法杀掉, 很快netstat -antp |grep 8250 状态再次消失,cloudstack master平台监控主机记录由Up状态转为disconnect状态。不过毕竟不是down状态,较之前已经有了进步。
启动一个libvirtd -d看下

然后在cloudstack master平台上手工点击强制重新连接该主机,成功了。主机监控状态由disconnect转为Up,这时再次尝试杀掉6485仍然是不成功的,于是又在cloudstack master管理平台上尝试着点击操作了一下暂停vm命令,vm成功暂停。再返回服务器上观察原来hung死的libvirtd进程已经消失。

至此既恢复了平台对该主机的管控,也终止了libvirtd异常进程。问题初步归于cloudstack-agent在处理发送个libvirtd的信号上存在些小问题。以后再单独分析下jsvc进程,再现问题和根本解决。
问题反思
在处理服务异常的问题上,命令行参数不要用restart,用stop和kill来调试。说起来都是泪!