
内容简介
收集系统与应用相关信息能够帮助我们针对基础设施、服务器以及软件做出更为准确的判断与决策。
获取此类信息的方式多种多样,今天要介绍的Graphite不仅能够实现信息整理,同时亦可将其加以显示以简化归纳工作。
Graphite是一款出色的系统数据整理与可视化工具,其灵活性出色且能够根据大家的实际需要进行配置,从而通过各类指标追踪系统性能及运行状态。
在本教程中,我们将探讨如何在Ubuntu 14.04服务器上设置Graphite。
安装Graphite
在教程开头,我们需要下载并安装Graphite的各款组件,其中包括一款名为Carbon的Web应用型存储后端,外加whisper数据库工具库。
Graphite曾经相当难于安装。幸运的是,在Ubuntu 14.04当中,我们需要的全部组件都已经能够在默认库中找到。
下面更新本地软件包索引,而后安装必要软件包:
sudo apt-get update
sudo apt-get install graphite-web graphite-carbon
在安装过程中,系统会询问我们是否允许Carbon移除数据库文件以实现清洁安装。这里要选择“No”,否则可能破坏我们的运行状态。如果大家需要从头开始,则可选择手动移除相关文件(位于var/lib/graphite/whisper)。
安装完成后,Graphite还需要经过一系列配置方可真正发挥作用。
为Django配置数据库
尽管Graphite数据本身由Carbon与whisper数据库工具库负责处理,但该Web应用本身亦属于Django Python应用,因此需要对应的数据存储方案加以配合。
在默认情况下,我们可以利用SQLite3数据库文件实现配置。不过,这种解决办法无法提供完整而强大的关系数据库管理系统,因此我们选择利用PostgreSQL进行应用配置。PostgreSQL拥有严格的数据类型限定要求,而且能够发现各类导致潜在问题的异常状况。
安装PostgreSQL组件
我们可以通过以下命令安装该数据库软件及帮助软件包:
sudo apt-get install postgresql libpq-dev python-psycopg2
如此一来,我们就安装了数据库软件本身以及Graphite将要用于同数据库对接及通信的Python库。
创建数据库用户及数据库
接下来,我们需要创建一个PostgreSQL用户以及供Graphite使用的数据库。
我们以postgres系统用户使用psql命令以登录PostgreSQL:
sudo -u postgres psql
现在我们需要为Django创建数据库用户账户,以确保其能够对该数据库进行操作。我们将此用户称为graphite,并为其选定一条安全密码:
CREATE USER graphite WITH PASSWORD 'password';
现在我们可以创建数据库并将其设定为归属于我们的新用户。该数据库名称同样为graphite,从而简化二者之间的关系表达:
CREATE DATABASE graphite WITH OWNER graphite;
完成后,退出PostgreSQL会话:
\q
大家可能会看到提示信息,指出Postgres无法保存文件历史。由于不影响我们教程内的要求,因此忽略即可。
配置Graphite Web应用
现在,我们已经拥有了自己的数据库。不过,我们还需要修改Graphite设置以使用刚刚配置完成的各组件。下面一起来看。
首先打开Graphite Web应用配置文件:
sudo nano /etc/graphite/local_settings.py
我们要通过设置确保密钥以salt的方式使用,从而创建哈希值。取消SECRET_KEY参数注释并将其值变更为更长且惟一的内容。
SECRET_KEY = 'a_salty_string'
接下来,我们应当指定时区。这会影响到统计图形的显示时间。我们通过指定本列表(http://en.wikipedia.org/wiki/List_of_tz_database_time_zones)中的“TZ”列以设置时区。
TIME_ZONE = 'America/New_York'
我们还需要配置授权以实现图形数据保存。在同步数据库时,我们需要利用以下命令对用户账户进行授权:
USE_REMOTE_USER_AUTHENTICATION = True
在此之后,找到DATABASES目录定义。我们需要变更其值以反映Postgres信息,具体需要变更的包括NAME、ENGINE、USER、PASSWORD以及HOST键。
完成后,内容应如下所示:
DATABASES = {
'default': {
'NAME': 'graphite',
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'USER': 'graphite',
'PASSWORD': 'password',
'HOST': '127.0.0.1',
'PORT': ''
}
}
其中红色部分的值需要进行变更。确保将密码调整为我们在Postgres中为graphite用户选定的内容。
另外,还要确保对HOST参数进行设置。如果将其留空,Postgres会认为我们希望利用对等授权进行连接,在本示例中这样的设置无法正确完成验证。
完成后保存并退出。
同步数据库
现在大家已经填写了数据库区段,同步该数据库以创建正确的数据结构。
具体命令如下:
sudo graphite-manage syncdb
这时系统会要求我们为数据库创建一个superuser账户。创建新用户后,我们即可登录至此界面。名称任意指定即可,此界面可用于保存并修改图形。
配置Carbon
现在数据库已经准备就绪,下一步是配置Graphite的存储后端Carbon。
首先,我们需要在引导过程中启用carbon服务。打开该服务的配置文件:
sudo nano /etc/default/graphite-carbon
其中只包含一条参数,指定该服务是否在引导过程中启动。将值变更为“true”:
CARBON_CACHE_ENABLED=true
保存并退出。
接下来打开Carbon配置文件:
sudo nano /etc/carbon/carbon.conf
其中大部分配置条目无需修改,下面来看需要调整的部分。
将指令设置为true以启动日志保留:
ENABLE_LOGROTATION = True
保存并退出。
配置Storage Schema
现在打开storage schema文件。其会告知Carbon各值的保存时长以及值的相关细节:
sudo nano /etc/carbon/storage-schemas.conf
其中我们会看到以下条目:
[carbon]
pattern = ^carbon\.
retentions = 60:90d
[default_1min_for_1day]
pattern = .*
retentions = 60s:1d
此文件目前被定义为两部分,其一为决定如何处理来自Carbon自身的数据。Carbon配置要求存储部分自身性能指标。下方定义处的表达意为捕捉全部数据,即作用于任何不符合另一部分要求的数据。其负责定义默认处理策略。
作为区段标题的括号内部分作为新定义,在每个区段之内,都会有一条模式定义与一条数据保留策略。
模式定义是一条正则表达式,用于匹配一切被发送至Carbon的信息。此信息中包含一条指标名称,指明其负责检查的部分。在以上示例中,该模式会检查相关指标是否以“carbon.”字符串开头。
而数据保留策略则由多组数字定义。每组数字由一条时长间隔(即指标的记录频率)、冒号再加上各值保存时长所构成。大家可以通过逗号分隔的方式定义多组数字。
在本次演示中,我们将定义一个新schema,其将匹配我们之后将要用到的一条test值。
在默认部分之前,为test值添加另一部分,内容如下:
[test]
pattern = ^test\.
retentions = 10s:10m,1m:1h,10m:1d
其将匹配任意以“test.”开头的指标,负责将收集到的数据与相关细节进行三次保存。第一条归档定义(10s:10m)将每10秒创建一个数据点,且值保存时长仅为10分钟。
第二条归档(1m:1h)将每分钟创建一个数据点,其收集上一分钟产生的数据(共6个点,因此前一条归档会每10秒创建1个点)并汇总为新的数据点。在默认情况下,其以汇聚方式完成数据创建,我们稍后会对此加以调整。其数据存储时长则为1小时。
最后一条归档定义则创建为(10m:1d),即每10分钟生成一个数据点,数据汇聚方式与第二条归档定义相同,数据存储时长则为1天。
在请求Graphite中的信息时,其会从符合时间帧的区间内返回细化程度最高的信息。因此如果我们查询过去5分钟内的指标,则信息会提取自第一条归档。而如果要求针对过去50分钟内的指标生成图形,则数据则来自第二条归档。
完成后保存并退出。
关于存储聚合方法
在将高度细节化的信息聚合为广义数字时,Carbon实际采用的数据聚合方式对于我们理解指标准确性而言至关重要。每一次聚合,Graphite都会生成一套关于指标的低细节水平版本,正如我们之前在test schema中创建的第二与第三条归档。
如上所述,其默认操作为在聚合时提取平均值。这意味着Carbon会对各数据点进行平均值计算以创建数字结果。
但这种方式有时候可能与我们的要求相冲突。举例来说,如果我们希望查询某一跨越多个时间段的事件的总体时间数字,则需要将各数据点相加以创建总体数据点——而非取平均值。
我们可以在storage-aggregation.conf文件当中定义需要的聚合方式。首先将该文件由Carbon examples目录中复制到我们的Carbon配置目录:
sudo cp /usr/share/doc/graphite-carbon/examples/storage-aggregation.conf.example /etc/carbon/storage-aggregation.conf
在文本编辑器中打开该文件:
sudo nano /etc/carbon/storage-aggregation.conf
此文件的内容与上一个文件颇为相似,我们可以在其中找到以下条目:
[min]
pattern = \.min$
xFilesFactor = 0.1
aggregationMethod = min
这部分的名称与模式与storage-schemas文件完全一致,只不过名称为任意内容,而模式则与我们定义的指标相配备。
其中XFilesFactor是一条有趣的参数,它允许我们为Carbon需要进行聚合的值指定最小百分比。在默认情况下,全部值都被设置为0.5,意味着在创建聚合点时,高细节数据至少要占50%。
我们可以利用这种方式确保创建出的数据点不至于忽略掉实际状态。例如,如果数据中的70%由于网络问题而发生丢包,那么大家当然不可能使用仅包含30%数据所创建出的数据点。
下面来看聚合方法的定义。我们可以取平均值、求和值、最新值、最大值与最小值。选择了错误的值可能会导致数据记录发生问题。正确的选择当然取决于我们需要追踪的实际指标。
注意:必须保证向Graphite发送数据点的频度要高于最低归档保留时长,否则部分数据可能丢失!
这是因为Graphite只会在将高细节归档转化为常规归档时采用聚合处理,而在创建高细节度数据点时,其只会在时间间隔之后写入最近数据。我们将在本系列的后续教程中探讨SatasD,其能够更为频繁地缓存并聚合数据,从而解决这一问题。
保存并退出。
在完成后,可利用以下命令启动Carbon:
sudo service carbon-cache start
安装并配置Apache
要使用Web界面,我们还需要安装并配置Apache Web服务器。Graphite当中包含面向Apache的配置文件,因此使用起来更为便捷。
利用以下命令安装各组件:
sudo apt-get install apache2 libapache2-mod-wsgi
安装完成后,我们需要禁用默认虚拟主机文件,因为其会与我们的新文件相冲突:
sudo a2dissite 000-default
接下来把Graphite Apache虚拟主机文件复制到可用站点目录当中:
sudo cp /usr/share/graphite-web/apache2-graphite.conf /etc/apache2/sites-available
而后启用该虚拟主机文件:
sudo a2ensite apache2-graphite
重载该服务以应用各项变更:
sudo service apache2 reload
Checking out the Web Interface
现在我们已经完成全部配置工作,接下来检查Web界面。
在浏览器中通过域名或者IP地址访问我们的服务器:
http://server_domain_name_or_IP
现在我们需要登录以保存全部生成的图形设置。点击顶部菜单栏中的“Login”按钮并输入同步Django数据库时配置的用户名与密码。
接下来,如果大家在左侧窗格内打开Graphite树形结构,则会看到Carbon条目。我们可以在这里找到Carbon所记录的数据图形。点击选定所需选项,在这里我们对接收到的指标进行图形化处理,同时更新操作指标。
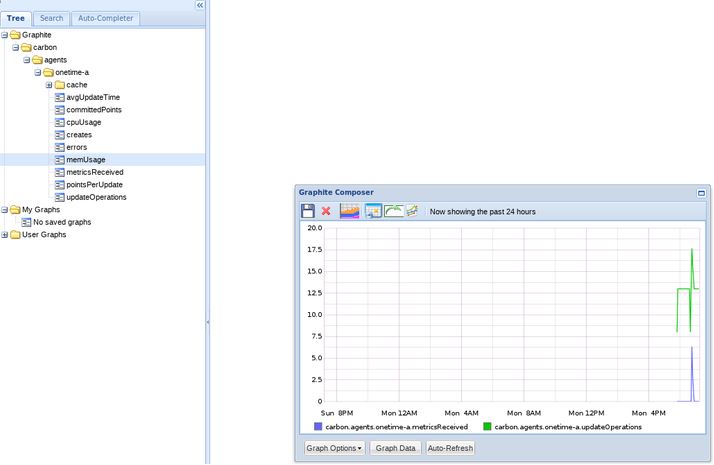
现在,我们尝试向Graphite发送部分数据。在进行过程中,请注意大家几乎从未以这种方式向Graphite发送状态信息。虽然还有很多更好的实现方式,但这样的方式有助于显示当前后台运作情况,并帮助我们了解Graphite在数据处理方面的限制条件。我们将在之后的文章中就此进行深入探讨。
指标信息中需要包含一条指标名称、一个值以及一个时间戳。我们可以在终端中实现这些要求。首先创建一个与test storage schema相匹配的值。我们还需要在聚合时为其匹配一条能够对各值相加的定义。而后利用data命令生成时间戳。命令如下:
echo "test.count 4 `date +%s`" | nc -q0 127.0.0.1 2003
如果大家刷新页面,则会在屏幕左侧发现Graphite树,其中即包含有我们的新test指标。重复发送以上命令,每次发送之间至少相隔10秒。请记住,Graphite在最小间隔中获取到多个值时,只会保留最近的一个。
现在,我们可以在Web界面中要求Graphite显示过去8分钟内的全部数据点。在test指标图形中点击白底绿箭头图标——将鼠标悬停于其上将显示“Select Recent Data”说明:
在弹出窗口中选择8分钟,点击“Update Graph”图标以获取这些最新数据。大家这时会看到一份信息量极低的图形——这是因为我们只向其发送了几个值,而且全部值皆为“4”,因此图形中不会体现出任何变化。
但如果我们查看过去15分钟的图形(假定我们已经多次发送该命令,间隔超过10秒但低于1分钟),则结果将有所不同
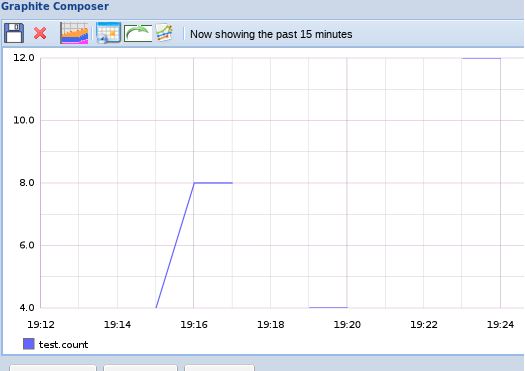
这是因为我们的第一条归档的数据保存时长不足15分钟,因此Graphite会从第二条归档中获取数据以完成图形渲染。之所以结果有所不同,是因为我们向Graphite发送了一条“count”指标,其与我们的聚合定义之一相匹配。
所谓count聚合方法会要求Graphite将接收到的各值相加,而非取平均值。如大家所见,我们选定的这条聚合方法非常重要,因为其定义了如何根据高细节数据生成数据点。
总结
现在我们已经完成了Graphite的安装与设置工作,但目前能够实现的功能还比较有限。我们不可能永远手动为其提供数据,也希望能够在较短间隔当中使用更多指标并确保其不会丢弃任何数据。为了满足这些要求,我们需要使用其它工具来解决问题。