
本篇文章主要介绍如何在ubuntu上使用Python来调用Hadoop,会以一个完整的MapReduce任务来说明。
首先需要下载Hadoop,我使用的是Hadoop-2.7.3,稳定版的是Hadoop-2.7.2.但是官网上没有给出Hadoop-2.7.2的直接教程,所以建议下载Hadoop-2.7.3.然后需要下载Hadoop Streaming Python,直接百度或者谷歌这三个关键词然后下载即可,这里推荐hadoop streaming-2.7.2.jar, 亲测能用,而且可以用在hadoop-2.7.3上面。
除此之外,python和JDK是必备工具。python不用安装,系统自带。Java的安装可以去Oracle官网下载,最后是下载JDK而不是JRE,因为JDK的功能更全面,JRE是JDK的子集。
有几个下载地址的链接:
hadoop的官网链接 http://hadoop.apache.org/releases.html
JDK的官网链接 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Note: hadoop下载完之后,有个JAVA_HOME的环境变量需要配置成JDK的安装路径,具体细节可以参考http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/SingleCluster.html这个链接里面对于单节点和伪分布式模式的配置讲的很清楚。
接下来进入正题!
1.单机模式
直接参考下方的附内容。
2.伪分布式模式
上面的那个链接中虽然也提到了如何配置伪分布式模式,但运行起来还是有点问题。在这里我会一步步地说明如何配置。
(1)测试文本的下载地址:http://www.gutenberg.org/files/5000/ 点击下载zip文件然后解压即可。
(2)准备mapper和reducer文件。这两段代码是我从一个网站上直接粘过来的,链接在这里http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/。需要注意的是,在把这两段程序写到mapper.py和reducer.py之后,使用chmod +x 命令给予这两个文件可执行权限。
#!/usr/bin/env python
#mapper
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word, 1)
###############################################
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
(3)启动HDFS环境。ssh localhost这条命令有时候不执行也行,建议每次都用。
ssh localhost
切换到安装hadoop的目录,然后执行:
bin/hdfs namenode -format
sbin/start-dfs.sh
如果一切顺利,这时在浏览器中输入http://localhost:50070/会看到HDFS的overview。如果不顺利,有一个很可能的原因是你多次format了HDFS,解决这个问题有两个办法。第一个办法是重启电脑,第二个办法是到/tmp目录下把所有带有hadoop的文件全部删掉。
(4)创建用户目录和上传待处理文件。
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/<username>
然后把待处理的文件拷贝到HDFS中。
bin/hdfs dfs -copyFromLocal ~/Desktop/hadoop_tu/testData.txt /user/wjk/data1.txt
使用ls命令可以查看HDFS目录下的文件。
bin/hdfs dfs -ls /user
bin/hdfs dfs -ls /user/wjk
(5)执行MapReduce程序。bin/hadoop jar是执行hadoop streaming的意思,后边接的是jar文件在电脑本机的位置;mapper和reducer后边接的是mapper和reducer文件在本机的位置;input后边接的是HDFS中input文件的位置,output后边接的是需要在HDFS中设置的输出文件的位置。
bin/hadoop jar ~/hadoop-2.7.3/hadoop-streaming-2.7.2.jar -mapper ~/Desktop/hadoop_tu/mapper.py -reducer ~/Desktop/hadoop_tu/reducer.py -input /user/wjk/data1.txt -output /user/wjk/output
执行成功后,可以看到类似的画面:
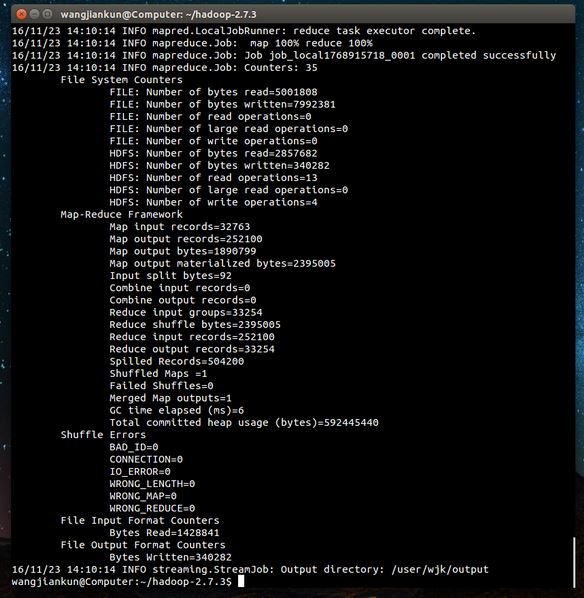
我们可以在输出目录中查看结果:
bin/hdfs dfs -cat /user/wjk/output/part-00000
这里part-00000是hadoop默认的输出文件的名字。
也可以把输出文件拷贝到本地:
bin/hdfs dfs -copyToLocal /user/wjk/output/part-00000 ~/Desktop/
至此,我们已经完成了一个从无到有的MapReduce任务。
附:
