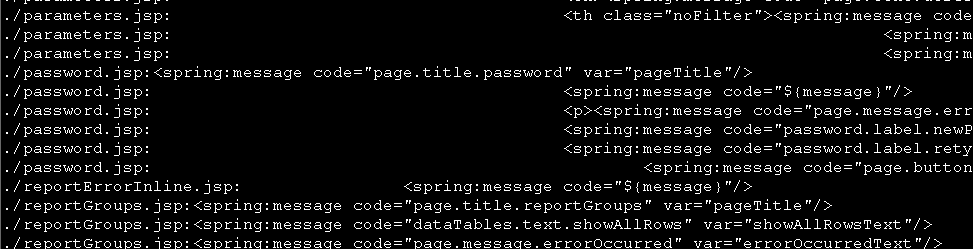
由于一些需求需要,遍历某目录先所有文件,找出某行的关键信息。
如:搜索所有 jsp 文件的内容,找出"spring:message"所在行,并取引号内的字符串。
(如下图,取粉色框中的字符串)
第一步,遍历文件:
find -name "*.jsp"
第二步输出所有文件内容,太多了!所以直接过滤关键字行。
find -name "*.jsp" -print -exec cat {} \; | grep "spring:message"
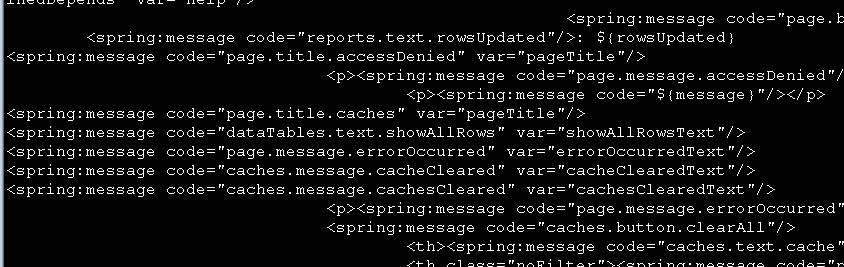
第三步,把每行前面的空字符去掉
find -name "*.jsp" -print -exec cat {} \; | grep "spring:message" | sed -e 's/^[ \t]*//'
find -name "*.jsp" -print -exec cat {} \; | grep "spring:message" | sed 's/[[:space:]]//g'
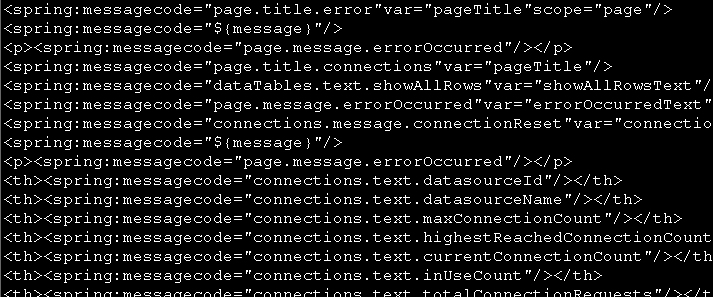
第四步,按双引号分割行,取第二列(比较有规律!)
find -name "*.jsp" -print -exec cat {} \; | grep "spring:message" | sed 's/[[:space:]]//g' | cut -d"\"" -f2
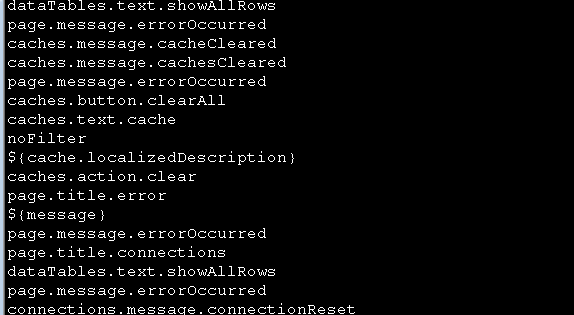
第五步排除有某些字符的行(如排除右大括号的行)
find -name "*.jsp" -print -exec cat {} \; | grep "spring:message" | sed 's/[[:space:]]//g' | cut -d"\"" -f2 | grep -v "}"
第六步,排序并去重复行
find -name "*.jsp" -print -exec cat {} \; | grep "spring:message" | sed 's/[[:space:]]//g' | cut -d"\"" -f2 | grep -v "}" | sort -u
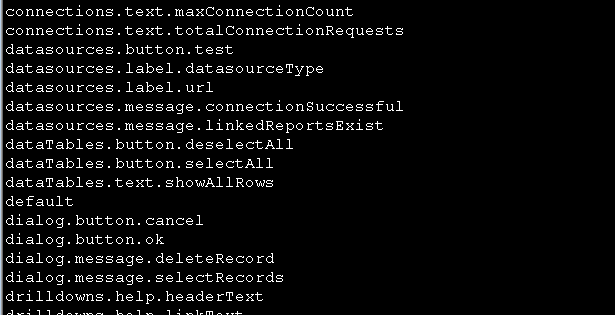
完成!
另:搜索某目录下所有文件内容,找出关键字所在的行,同时输出所在文件及行内容
grep "spring:message" ./*