
写在前边的话
ELK stack是指由Elasticsearch,Logstash,Kibana三个组件结合起来而构成的一个日志收集,分析,可视化的一个套件。
环境说明
Deepin15.2
Java 1.8.0
Elasticsearch 2.4.0
Logstash 2.4.0
Kibana 4.6.1
部署路径:/opt/elk
官网下载地址(配套下载,避免出现版本不匹配问题):https://www.elastic.co/products
简单介绍
1:E->Elasticsearch
es和solr比较类似,都是基于lucene的来提供的搜索服务。但是在高并发的表现上,ES的负载均衡效果是优于solr的。
Elasticsearch 是基于 Lucene 的近实时搜索平台,它能在一秒内返回你要查找的且已经在 Elasticsearch 做了索引的文档。它默认基于 Gossip 路由算法的自动发现机制构建配置有相同 cluster name 的集群,但是有的时候这种机制并不可靠,会发生脑裂现象。鉴于主动发现机制的不稳定性,用户可以选择在每一个节点上配置集群其他节点的主机名,在启动集群时进行被动发现。
Elasticsearch 中的 Index 是一组具有相似特征的文档集合,类似于关系数据库模型中的数据库实例,Index 中可以指定 Type 区分不同的文档,类似于数据库实例中的关系表,Document 是存储的基本单位,都是 JSON 格式,类似于关系表中行级对象。我们处理后的 JSON 文档格式的日志都要在 Elasticsearch 中做索引,相应的 Logstash 有 Elasticsearch output 插件,对于用户是透明的。
Hadoop 生态圈为大规模数据集的处理提供多种分析功能,但实时搜索一直是 Hadoop 的软肋。如今,Elasticsearch for Apache Hadoop(ES-Hadoop)弥补了这一缺陷,为用户整合了 Hadoop 的大数据分析能力以及 Elasticsearch 的实时搜索能力.
2:L->Logstash
Logstash 是一种功能强大的信息采集工具,类似于 Hadoop 生态圈里的 Flume。通常在其配置文件规定 Logstash 如何处理各种类型的事件流,一般包含 input、filter、output 三个部分。Logstash 为各个部分提供相应的插件,因而有 input、filter、output 三类插件完成各种处理和转换;另外 codec 类的插件可以放在 input 和 output 部分通过简单编码来简化处理过程。
3:K->Kibana
kibana是一个可以可以用来查看ES里数据的Web。在早期logstash有一个logstash-web,但是功能比较简单。咱们这里说的kibana严格意义上说是kibana4,是在2015年重构完成的一个版本。
ELK与Hadoop/Spark的比较
ELK应付常见的日志摘要和分析是没问题的,上PB级的数据量也不是难事。ELK简单、轻量、易扩展倒是真的,但数据容量,二次抽洗,以及周边生态,还是没有Hadoop来得好。elk在掌握简单的正则以后即可对任意数据进行抽取(要求半格式化数据),处理同样的数据Spark还需要学一门编程语言。
具体参考:
http://sanwen.net/a/kewgsbo.html
Elasticsearch的部署与head插件的安装
1:Elasticsearch的部署
解压到指定目录/opt/elk,并启动
sudo tar -zxvf /home/thinkgamer/下载/ELK/elasticsearch-2.4.0.tar.gz -C .
bin/elasticsearch
利用以下命令获取状态信息(得到的内容和下边图片上显示的是一样的)
curl -X GET http://localhost:9200/
也可以在浏览器窗口输入localhost:9200,可以看到类似于如下的界面
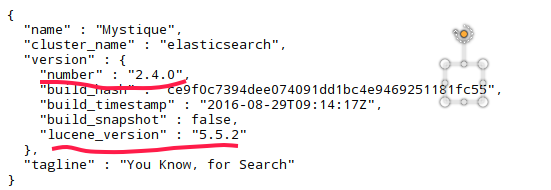
从中我们可以看出elasticsearch的版本为2.4.0,是基于lucene5.5.2开发的
2:安装head插件
执行命令
bin/plugin install mobz/elasticsearch-head
访问url:
http://localhost:9200/_plugin/head/
LogStash的部署
解压到/opt/elk目录下:
tar -zxvf /home/thinkgamer/下载/ELK/logstash-2.4.0.tar.gz -C .
这里针对这个input和output有三种情况
1.shell 端输入 shell 端输出
此种情况下,并不涉及elasticsearch和kibana,只是简单测试Logstash服务是否正常,预期将输入的内容结构化的输出到界面上
bin/logstash -e ‘input { stdin { } } output { stdout {} }’ &
提示:
Settings: Default pipeline workers: 4
Pipeline main started
这个时候由于我们定义的input和output是stdin和stdout,并没有进行额外的处理,所以你输入什么就会输出什么
thinkgamer@thinkgamer-pc:/opt/elk/logstash-2.4.0$ bin/logstash -e 'input{stdin{}} output{stdout{}}'
Picked up _JAVA_OPTIONS: -Dawt.useSystemAAFontSettings=gasp
Settings: Default pipeline workers: 4
Pipeline main started
qwewq
2016-09-25T05:14:04.819Z thinkgamer-pc qwewq
safdaas
2016-09-25T05:15:32.132Z thinkgamer-pc safdaas
我爱你
2016-09-25T05:15:34.792Z thinkgamer-pc 我爱你
PS:以下两种方式涉及kibana的web展示,所以在配置web输出后,需要进行的操作是creat动作,具体看kibana部署中的示例
2.shell端输入 web端展示
然后我们创建Logstash配置文件,并再次测试Logstash服务是否正常,预期可以将输入内容以结构化的日志形式打印在界面上(这里我们配置了Logstash作为索引器,将日志数据传送到elasticsearch中)
mkdir config
vim config/hello_search.conf
填写如下内容:
input { stdin { } }
output {
elasticsearch { hosts => "localhost" }
stdout { codec => rubydebug }
}
bin/logstash -f config/hello_search.conf
再次测试执行的效果:
thinkgamer@thinkgamer-pc:/opt/elk/logstash-2.4.0$ bin/logstash agent -f config/hello_search.conf
Picked up _JAVA_OPTIONS: -Dawt.useSystemAAFontSettings=gasp
Settings: Default pipeline workers: 4
Pipeline main started
sdf
[2016-09-25 13:28:21,997][INFO ][cluster.metadata ] [Arcademan] [logstash-2016.09.25] creating index, cause [auto(bulk api)], templates [logstash], shards [5]/[1], mappings [_default_]
[2016-09-25 13:28:22,758][INFO ][cluster.routing.allocation] [Arcademan] Cluster health status changed from [RED] to [YELLOW] (reason: [shards started [[logstash-2016.09.25][4]] ...]).
[2016-09-25 13:28:22,993][INFO ][cluster.metadata ] [Arcademan] [logstash-2016.09.25] create_mapping [logs]
{
"message" => "sdf",
"@version" => "1",
"@timestamp" => "2016-09-25T05:28:21.161Z",
"host" => "thinkgamer-pc"
}
受到方式
{
"message" => "受到方",
"@version" => "1",
"@timestamp" => "2016-09-25T05:28:30.998Z",
"host" => "thinkgamer-pc"
}
我爱你
{
"message" => "我爱你",
"@version" => "1",
"@timestamp" => "2016-09-25T05:28:58.399Z",
"host" => "thinkgamer-pc"
}
我们可以在Elastic的web界面上看到
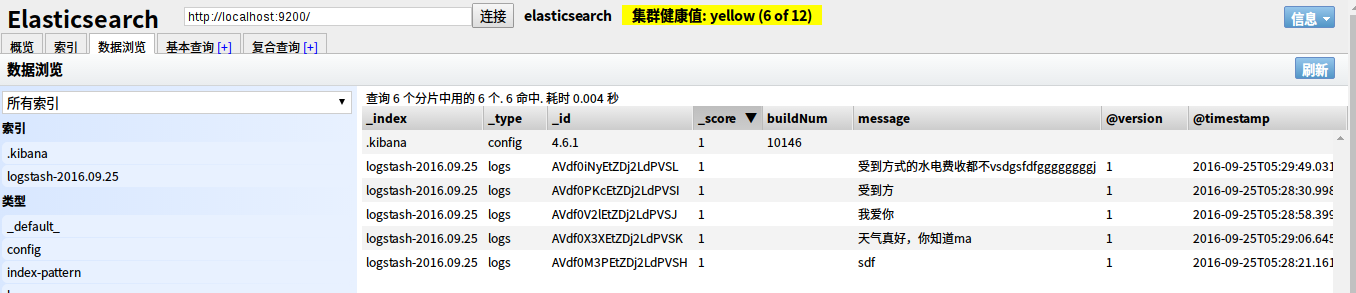
3.监测指定文件,web展示
在/opt/elk/testlog 下有两个文件,分别是access.log 和error.log,我们通过echo往这两个文件追加内容,来测试整个日志收集系统是否可行
vim /opt/elk/logstash-2.4.0/config/hello_search.conf
input {
file {
type =>"syslog"
path => ["/opt/elk/auth.log" ]
}
syslog {
type =>"syslog"
port =>"5544"
}
}
output {
stdout { codec=> rubydebug }
elasticsearch {hosts => "localhost"}
}
启动
bin/logstash -f config/hello_search.conf
这里需要再次打开http://localhost:5601/ 进行create
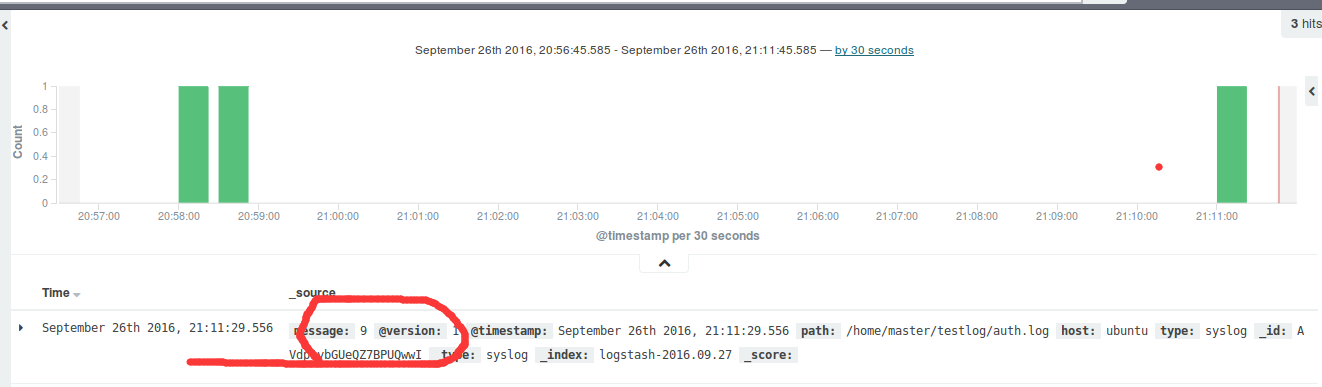
测试效果
echo 9 >> auth.log
Kibana部署
解压到指定目录/opt/
tar -zxvf /home/thinkgamer/下载/ELK/kibana-4.6.1-Linux-x86_64.tar.gz -C .
启动kibana
bin/kibana
web访问:http://localhost:5601/
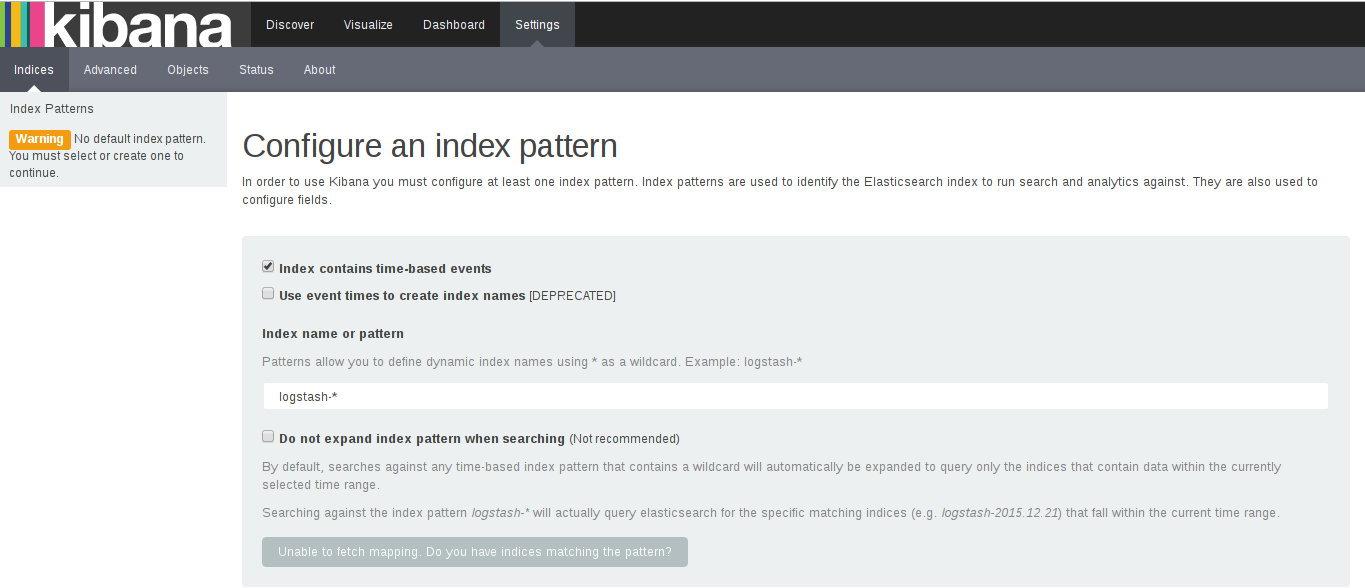
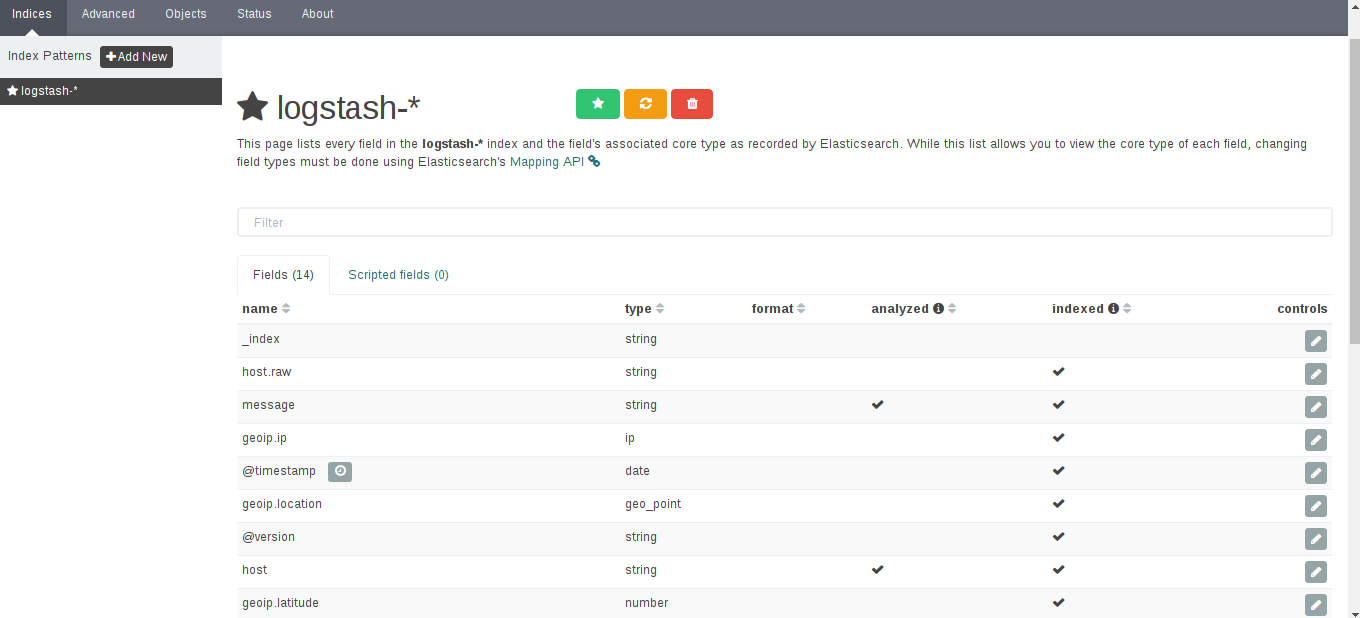
这里需要配置一个索引:
默认,Kibana的数据被指向Elasticsearch,使用默认的logstash-*的索引名称,并且是基于时间的,点击“Create”即可。
看到如下界面说明OK了
点击Discover可以看到,我们刚才在终端测试的输入
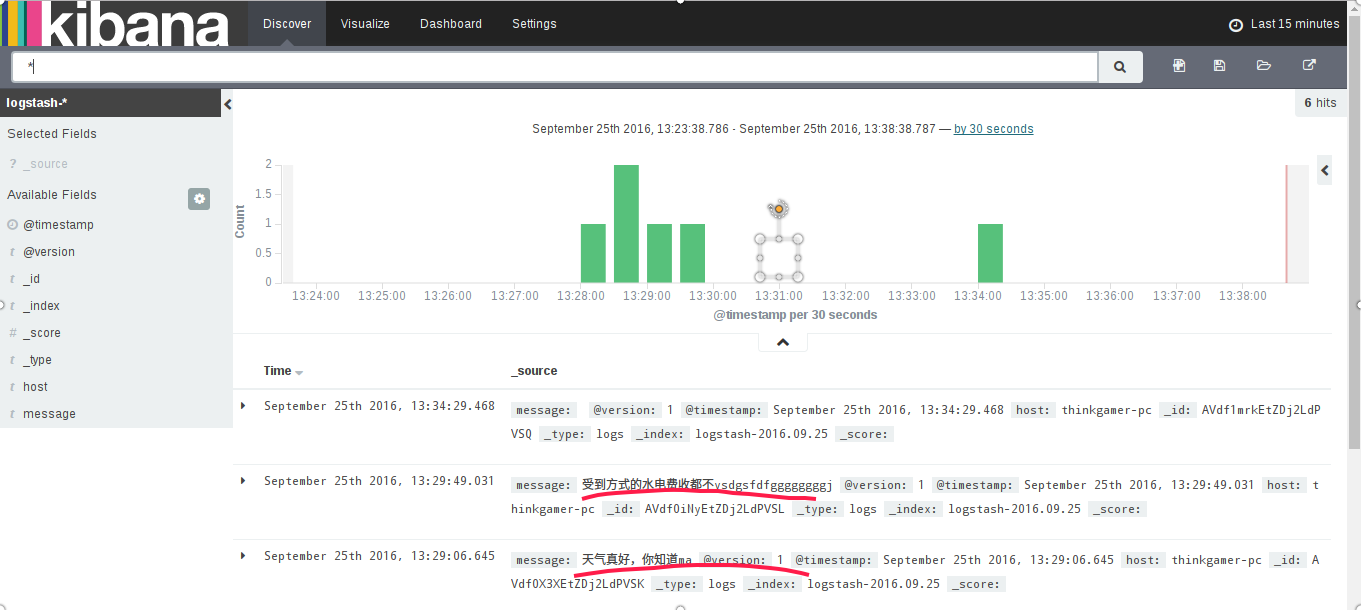
至此,一个小的 ELK stack日志分析系统已经完成了。