
1.系统环境
Ubuntu 16.04
vmware
Hadoop 2.7.0
Java 1.8.0_111
master:192.168.19.128
slave1:192.168.19.129
slave2:192.168.19.130
2.部署步骤
2.1.Basic Requirements
1]、添加 hadoop 用户,并添加到 sudoers
sudo adduser hadoop
sudo vim /etc/sudoers
添加如下:
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL
2]、切换到 hadoop 用户:
su hadoop
3]、修改 /etc/hostname 主机名为 master
sudo vim /etc/hostname
4]、修改 /etc/hosts
127.0.0.1 localhost
127.0.1.1 localhost.localdomain localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
# hadoop nodes
192.168.19.128 master
192.168.19.129 slave1
192.168.19.130 slave2
5]、安装配置 Java 环境
下载 jdk1.8 解压到 /usr/local 目录下(为了保证所有用户都能使用),修改 /etc/profile,并生效:
# set jdk classpath
export JAVA_HOME=/usr/local/jdk1.8.0_111
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
source /etc/profile
验证 jdk 是否安装配置成功
hadoop@master:~$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
6]、安装 openssh-server
sudo apt-get install openssh-server
7]、对于 slave1 和 slave2 可采用虚拟机 clone 的方法实现复制,复制主机后注意修改 /etc/hostname 为 slave1 和 slave2
8]、配置 master 节点可通过 SSH 无密码访问 slave1 和 slave2 节点
ssh-keygen -t rsa
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
将生成的 authorized_keys 文件复制到 slave1 和 slave2 的 .ssh目录下
scp .ssh/authorized_keys hadoop@slave1:~/.ssh
scp .ssh/authorized_keys hadoop@slave2:~/.ssh
测试 master 节点无密码访问 slave1 和 slave2 节点:
ssh slave1
ssh slave2
输出:
hadoop@master:~$ ssh slave1
Welcome to Ubuntu 16.04.1 LTS (GNU/Linux 4.4.0-31-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Last login: Mon Nov 28 03:30:36 2016 from 192.168.19.1
hadoop@slave1:~$
2.2.Hadoop 2.7 Cluster Setup
1]、hadoop 用户目录下解压下载的 hadoop-2.7.0.tar.gz
hadoop@master:~/software$ ll
total 205436
drwxrwxr-x 4 hadoop hadoop 4096 Nov 28 02:52 ./
drwxr-xr-x 6 hadoop hadoop 4096 Nov 28 03:58 ../
drwxr-xr-x 11 hadoop hadoop 4096 Nov 28 04:14 hadoop-2.7.0/
-rw-rw-r-- 1 hadoop hadoop 210343364 Apr 21 2015 hadoop-2.7.0.tar.gz
2]、配置 hadoop 的环境变量
sudo vim /etc/profile
配置如下:
# set hadoop classpath
export HADOOP_HOME=/home/hadoop/software/hadoop-2.7.0
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export CLASSPATH=$CLASSPATH:.:$HADOOP_HOME/bin
3]、配置 hadoop 的配置文件,主要配置 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 文件。
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- master: /etc/hosts 配置的域名 master -->
<value>hdfs://master:9000/</value>
</property>
</configuration>
######################
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/software/hadoop-2.7.0/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/software/hadoop-2.7.0/dfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
######################
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
######################
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
4]、修改env环境变量文件,为 hadoop-env.sh、mapred-env.sh、yarn-env.sh 文件添加 JAVA_HOME:
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8.0_111/
5]、配置 slaves 文件
slave1
slave2
6]、向 slave1 和 slave2 节点复制 hadoop2.7.0 整个目录至相同的位置
hadoop@master:~/software$ scp -r hadoop-2.7.0/ slave1:~/software
hadoop@master:~/software$ scp -r hadoop-2.7.0/ slave2:~/software
2.3.Start Hadoop cluster from master
1]、初始格式化文件系统 bin/hdfs namenode -format
hadoop@master:~/software/hadoop-2.7.0$ ./bin/hdfs namenode -format
输出 master/192.168.19.128 节点的 NameNode has been successfully formatted.
......
16/11/28 05:10:56 INFO common.Storage: Storage directory /home/hadoop/software/hadoop-2.7.0/dfs/namenode has been successfully formatted.
16/11/28 05:10:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
16/11/28 05:10:56 INFO util.ExitUtil: Exiting with status 0
16/11/28 05:10:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.19.128
************************************************************/
启动 Hadoop 集群 start-all.sh
hadoop@master:~/software/hadoop-2.7.0$ ./sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-namenode-master.out
slave2: starting datanode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-datanode-slave2.out
slave1: starting datanode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-datanode-slave1.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /home/hadoop/software/hadoop-2.7.0/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/software/hadoop-2.7.0/logs/yarn-hadoop-resourcemanager-master.out
slave2: starting nodemanager, logging to /home/hadoop/software/hadoop-2.7.0/logs/yarn-hadoop-nodemanager-slave2.out
slave1: starting nodemanager, logging to /home/hadoop/software/hadoop-2.7.0/logs/yarn-hadoop-nodemanager-slave1.out
jps 输出运行的 java 进程:

浏览器查看 HDFS:http://192.168.19.128:50070
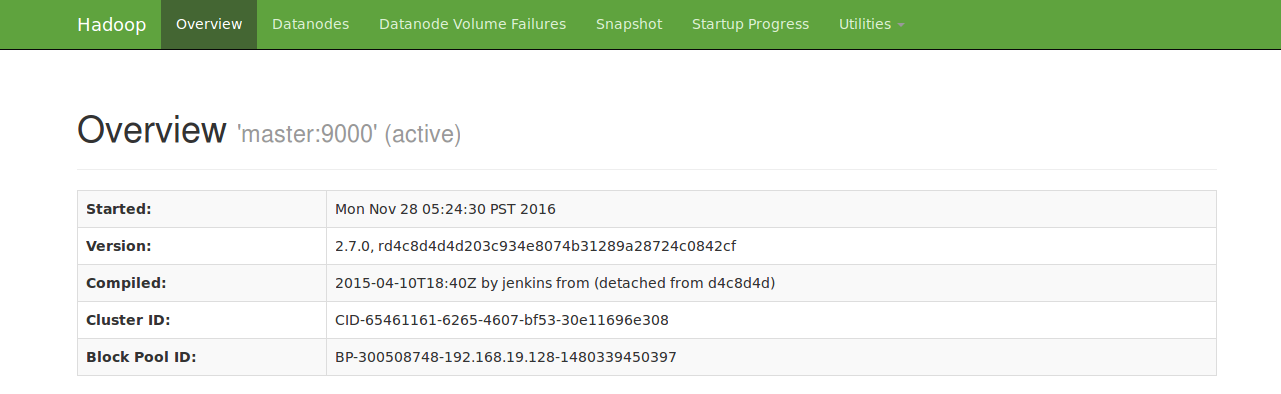
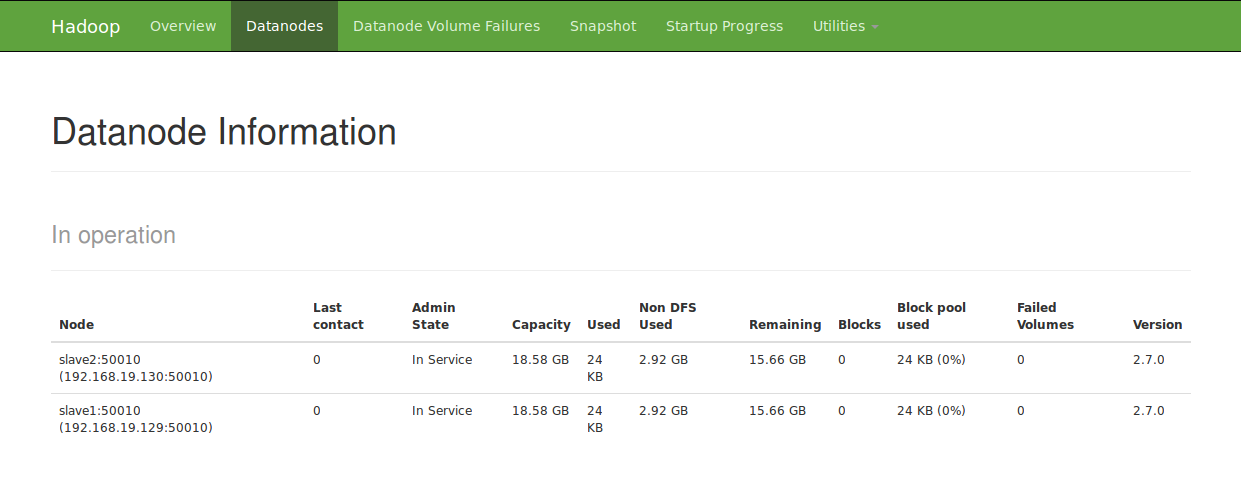
浏览器查看 mapreduce:http://192.168.19.128:8088
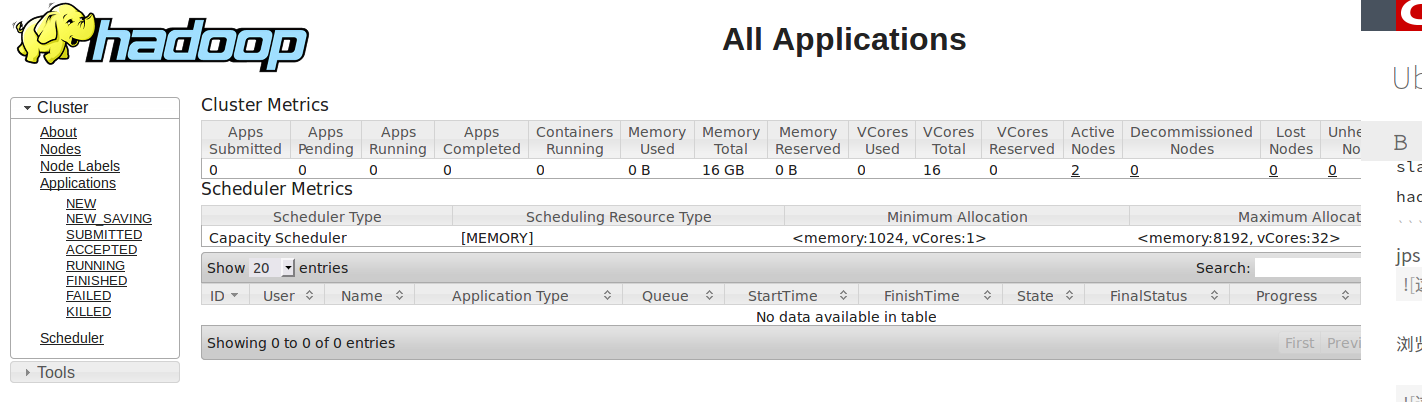
注意:在 hdfs namenode -format 或 start-all.sh 运行 HDFS 或 Mapreduce 无法正常启动时(master节点或 slave 节点),可将 master 节点和 slave 节点目录下的 dfs、logs、tmp 等目录删除,重新 hdfs namenode -format,再运行 start-all.sh
2.4.Stop Hadoop cluster from master
./sbin/stop-all.sh
hadoop@master:~/software/hadoop-2.7.0$ ./sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
slave2: stopping datanode
slave1: stopping datanode
Stopping secondary namenodes [master]
master: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
slave2: stopping nodemanager
slave1: stopping nodemanager
no proxyserver to stop