
1.引言
除了使用Wordpress插件备份数据库外,最近想到一种更棒的办法备份所有文章,就是自动将每篇文章生成PDF保存到本地。
本文记录了如何借助Python完成这项有趣任务。
2.准备工作
注意:以下所有操作均在Ubuntu 16.04系统上完成。
安装wkhtmltopdf,该工具是生成PDF的核心程序。
sudo apt update
sudo apt install wkhtmltopdf
安装Python实用包:
requests模块(用于访问博客URL,下载博客HTML文档):sudo pip3 install requests
BeautifulSoup4模块(用于解析HTML文档):sudo pip3 install BeautifulSoup4
pdfkit模块(该模块是对wkhtmltopdf命令的包装):sudo pip3 install pdfkit
确保本机网络正常,博客可以正常访问
3.思路
使用request.get(url)方法,先获得博客首页(我的博客首页显示的是最新发表的文章列表),找到第一篇文章的入口链接blog_url;
使用request.get(blog_url)方法,可以获得一篇文章的HTML内容;借助BeautifulSoup模块,获得文章内容,标题,分类等信息,然后使用pdfkit生成PDF文档保存到指定位置;
借助上一步获得的HTML文档,找到下一个将被访问的文档链接。如果没有链接,那么算法结束;否则,获取这个链接,并回到第二步重复执行。
4.实现
import requests
import os
from bs4 import Tag, BeautifulSoup
import pdfkit
# 控制生成的pdf格式
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': 'UTF-8'
}
def get_valid_name(name):
"""
过滤掉名称中不太适合作为文件名的字符
"""
invalid_chars = ("\\", "/", ":", "*", "<", ">", "|")
for x in invalid_chars:
if x in name:
name = name.replace(x, ' ')
return name
def get_first_url(soup):
if isinstance(soup, BeautifulSoup):
return soup.find('article').header.h2.a['href']
return ''
def get_next_url(soup):
if isinstance(soup, BeautifulSoup):
previous = soup.find('div', {'class': 'nav-previous'})
if previous:
return previous.a['href']
return ''
def get_pure_article(content):
if isinstance(content, Tag):
# 构建新的文章,只包括文章内容
new_soup = BeautifulSoup('''<html lang="zh-CN">
<head><meta http-equiv="content-type" content="text/html;charset=utf-8"></head>
<body></body></html>''', 'lxml')
new_soup.body.append(content)
return str(new_soup)
else:
return None
def get_article_title(content):
if isinstance(content, Tag):
return content.header.h1.text
else:
return '未命名'
def get_article_category(content):
if isinstance(content, Tag):
return content.header.div.span.text.split('->')[-1].strip()
else:
return '未分类'
def save_article(soup):
if isinstance(soup, BeautifulSoup):
# 获得文章内容
content = soup.find('article')
# 得到文章标题名称
title = get_article_title(content)
# 得到文章的分类信息
category = get_article_category(content)
# 创建存放文章的分类目录
if not os.path.exists(os.path.join('archives', category)):
os.mkdir(os.path.join('archives', category))
# 实际保存后的文件名称
name = '{}'.format(get_valid_name('{}'.format(title)))
try:
print('正在生成文件:{}.pdf,请稍等...'.format(title))
article = get_article_title(content)
if article:
# 生成PDF文件,这里的css文件是博客使用的样式
pdfkit.from_string(article, os.path.join('archives', category, '{}.pdf'.format(name)),
options=options, css='style.css')
return True
except Exception as e:
print(str(e))
return False
return False
def main():
url = 'http://blog.chriscabin.com'
print('开始整理:{},请耐心等待...'.format(url))
main_page = requests.get(url).text
# 第一篇文章作为入口,可以依次查找下一篇文章
url = get_first_url(BeautifulSoup(main_page, 'lxml'))
# 循环读取每篇文章,再保存
count = 0
while url != '':
count += 1
page_soup = BeautifulSoup(requests.get(url).text, 'lxml')
save_article(page_soup)
url = get_next_url(page_soup)
print('全部完成,共计{}篇文章,谢谢使用!'.format(count))
if __name__ == '__main__':
main()
效果
执行过程截图:
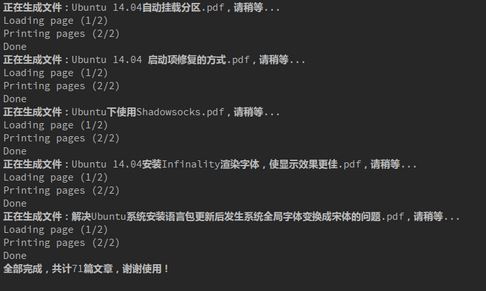
生成的文档分类截图:

生成的效果截图:
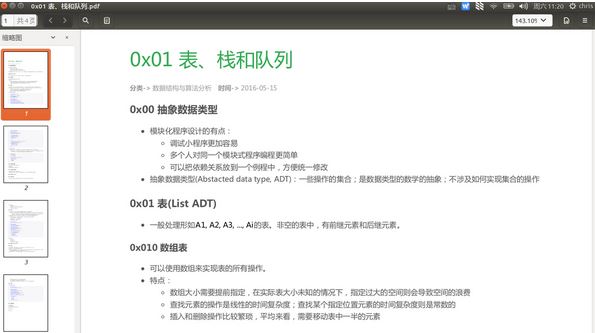
注意
在使用wkhtmltopdf程序生成PDF时,容易出现中文乱码的问题(注意不是因为中文字体缺失的问题,中文是可以显示的,我在Ubuntu上默认使用微软雅黑字体),经过尝试后发现,需要在HTML中指定charset="utf-8"才能让中文正常显示。