在ubuntu环境下,使用scrapy定时执行抓取任务,由于scrapy本身没有提供定时执行的功能,所以采用了crontab的方式进行定时执行:
1.首先编写脚本cron.sh
#! /bin/sh
export PATH=$PATH:/usr/local/bin
cd /home/ubuntu/lecture/Lecture_crawler
nohup scrapy crawl jnuISAT > spider.log 2>&1 &
nohup scrapy crawl scutCS >> spider.log 2>&1 &
nohup scrapy crawl ScutSoftware >> spider.log 2>&1 &
nohup scrapy crawl tshIIIS >> spider.log 2>&1 &
nohup scrapy crawl SKLOIS >> spider.log 2>&1 &
2.下一步我们要做的事情是让我们的脚本可执行。使用 chmod 命令:
chmod 755 cron.sh
权限为755的脚本,则每个人都能执行,和权限为700的 脚本,只有文件所有者能够执行
【此处可以自己运行一下脚本确保没有错误】
3.执行,crontab -e,规定crontab要执行的命令和要执行的时间频率
# Edit this file to introduce tasks to be run by cron.
#
# Each task to run has to be defined through a single line
# indicating with different fields when the task will be run
# and what command to run for the task
#
# To define the time you can provide concrete values for
# minute (m), hour (h), day of month (dom), month (mon),
# and day of week (dow) or use '*' in these fields (for 'any').#
# Notice that tasks will be started based on the cron's system
# daemon's notion of time and timezones.
#
# Output of the crontab jobs (including errors) is sent through
# email to the user the crontab file belongs to (unless redirected).
#
# For example, you can run a backup of all your user accounts
# at 5 a.m every week with:
# 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/
#
# For more information see the manual pages of crontab(5) and cron(8)
#
# m h dom mon dow command
0 0 * * * sh /home/ws/Documents/Lecture_crawler/cron.sh
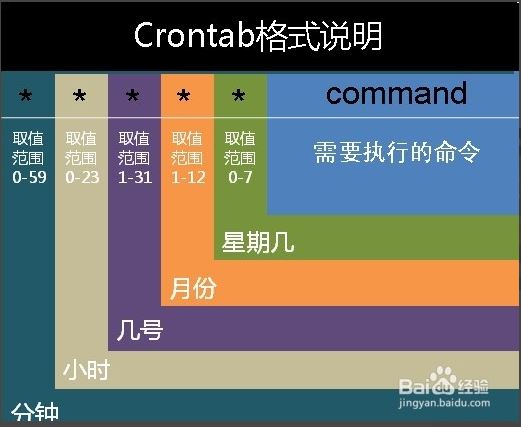
【crontab的常见格式:】
每分钟执行 */1 * * * *
每小时执行 0 * * * *
每天执行 0 0 * * *
每周执行 0 0 * * 0
每月执行 0 0 1 * *
每年执行 0 0 1 1 *
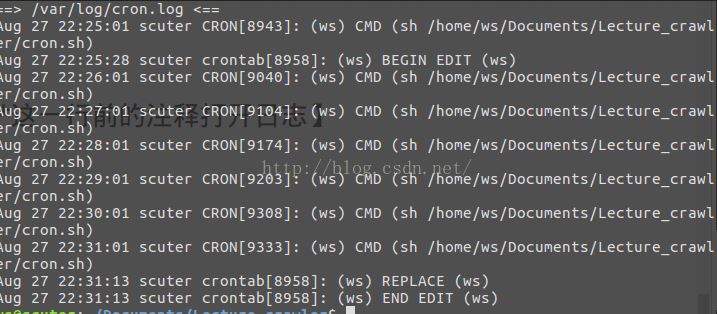
4.通过/var/log/下面的crontab的日志验证生效
【注:日志默认不开启,可用过vi /etc/rsyslog.d/50-default.conf ,将cron.*这一行前的注释打开日志】
开启后运行tail –f /var/log/cron.log
tail –f /var/log/cron.log