
在实际的工作中我们经常会遇到求数据的差集的问题。比如,原来数据库的某个表中有1000条数据,后来经过一些后续的变更,变成了1200条数据了。那么我们如何求得这多出来的200条数据究竟是哪一些呢?在此,我做了一个小小的总结,把求解此类问题的方法在此列出。为了后面叙述的方便,现把原来的1000条数据的文件命名为file1.txt,后来的1200条数据的文件命名为file2.txt。file1.txt和file2.txt的数据格式完全一样,就是每行放一个字段。此处有一个前提,较多的1200条数据的file2.txt完全包含较少的1000条数据的file1.txt,就是不存在file1.txt中存在,但是file2.txt中不存在的数据。
方法一:利用uniq命令
cat file1.txt file2.txt | sort | uniq -d
这个比较简单,首先是打开两个文件,然后进行排序,最后进行一个取唯一的操作。注意uniq后要有-d参数,其意思就是只打印出重复的行。就是前面两个文件中都存在的行。
方法二:利用comm命令
comm file1.txt file2.txt
但是利用comm命令有一个前提,就是这两个文件file1.txt和file2.txt必须是排序和唯一的(sort and uniq)。默认输出为三列,第一列为file1.txt-file2.txt,第二列为file2.txt-file1.txt,第三列为:file1.txt与file2.txt的差集。
方法三:利用awk命令
awk命令绝对算是Linux命令中功能超级强大的命令之一了。以下两种方式都可以得到想要的结果。
awk 'ARGIND==1{A[$0]} ARGIND>1&&!($0 in A){print $0}' file1.txt file2.txt
awk 'NR==FNR {A[$0]} NR>FNR&&!($0 in A) {print $0}' file1.txt file2.txt
在此首先解释一下awk的工作流程:
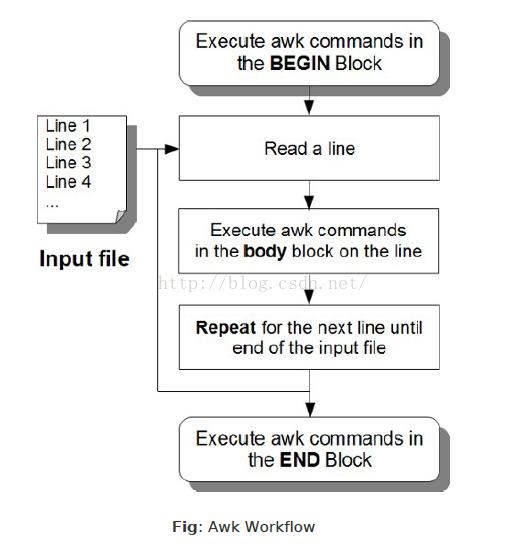
上图是awk最权威的一本书里面的描述。它简洁明了地描述了awk的工作流程。
ARGIND: The index in ARGV of the current file being processed.
NR: 代表记录的数目,相当于当前正在执行的当前的行数
FNR: File Number of Record
NR和FNR的区别:如果有两个输入文件,NR在两个文件之间会持续增长。当开始处理第二个文件时,NR不会被置为1,相反它会从第一个文件的最大值处继续递增。
所以上述两条命令的本质就是:当AWK处理的是第一个文件时,将第一个文件的每一行数据作为A的键;当处理到第二个文件时,如果读取的某一行数据在A中的键中不存在,就把它打印出来,这行数据就是文件1中不存在的数据。整个AWK过程处理完,就会把所有在文件2中存在但是在文件1中不存在的是数据给打印出来了。