
背景
在ubuntu终端,用diff命令比较两个源文件时,发现输出乱码,如下图所示:

原因
Ubuntu默认编码是UTF-8,可以用locale命令查看,在我电脑上查看结果如下:
LANG=zh_CN.UTF-8
LANGUAGE=zh_CN:en_US:en
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC=zh_CN.UTF-8
LC_TIME=zh_CN.UTF-8
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY=zh_CN.UTF-8
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER=zh_CN.UTF-8
LC_NAME=zh_CN.UTF-8
LC_ADDRESS=zh_CN.UTF-8
LC_TELEPHONE=zh_CN.UTF-8
LC_MEASUREMENT=zh_CN.UTF-8
LC_IDENTIFICATION=zh_CN.UTF-8
LC_ALL=
之所以会乱码,是因为我用diff命令比较的文件(这个文件是在windows环境下创建的,而Windows操作系统的简体中文默认编码字符集是GBK,GBK向下兼容GB2312编码)是GB2312的编码,而不是UTF-8编码。
UTF-8
UTF-8:Unicode TransformationFormat-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用1个字节,中文使用2~4个字节来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。
GBK
GBK是在国家标准GB2312的基础上扩容后的标准,它兼容GB2312。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码。
解决方法
解决方法有很多,这里写出我用的方法。
考虑到UTF-8是国际编码,通用性强,所以把GB2312编码的文件转换为UTF-8编码的就OK了。
转换工具是windows下的Notepad++;
Notepad++ is a free (as in “free speech” and also as in “free beer”) source code editor and Notepad replacement that supports several languages. Running in the MS Windows environment, its use is governed by GPL License.
这个软件的下载地址是:
https://notepad-plus-plus.org/
下载好后,我们用Notepad++打开需要转换的文件,在右下角会显示出文件的编码格式,比如:
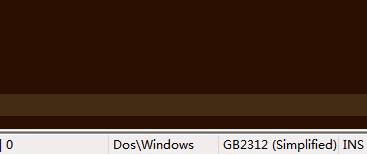
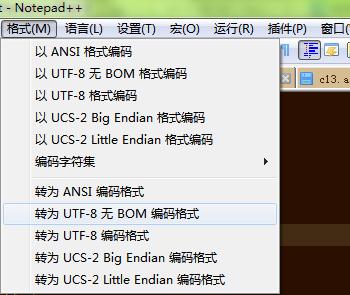
我们选择【格式】-【转为UTF-8无BOM编码格式】,然后保存即可。
附:UTF-8需要BOM吗
UTF-8以字节为编码单元,没有字节序问题,BOM仅仅用于表明其编码格式(signature),但不建议如此。因为UTF-8编码特征明显,无需BOM即可检测出是否为UTF-8格式(文件较短时可能不准确)。
Unicode标准并未要求或建议UTF-8编码使用BOM,但确实允许BOM出现在文件开头。带有BOM的Unicode文件有时会带来一些问题:
Linux/Unix系统未使用BOM,因为它会破坏现有ASCII文件的语法约定。
某些编辑器不会添加BOM,或者可以选择是否添加BOM(比如NotePad++)。
某些语法分析器可以处理字符串常量或注释中的UTF-8,但无法分析文件开头的BOM。
某些程序在文件开头插入前导字符来声明文件类型等信息,这与BOM的用途冲突。
顺便说一下,当我把汇编源文件变成带BOM的UTF-8格式时,在Linux环境下,NASM编译器根本不认识它,会报错。