
前言
最近再搞OCR的,用于识别日文报刊,是公司的一个日本项目,做的我是苦不堪言。最近把自己的工作内容写出来,也会做一个系列和专栏,欢迎关注!
想搞好这个OCR,需要读论文。好在只需要读4篇,都是Tesseract的作者Ray Smith写的。Tesseract目前被Google维护并开源,以后的前景应该会非常好。
按发表时间排序:
2007,An Overview of the Tesseract OCR Engine(https://github.com/guzhenping/the-Papers-and-Data-of-Tesseract-OCR-/blob/master/An%20Overview%20of%20the%20Tesseract%20OCR%20Engine.pdf)
2009,Hybrid Page Layout Analysis via Tab-Stop Detection(https://github.com/guzhenping/the-Papers-and-Data-of-Tesseract-OCR-/blob/master/Hybrid%20Page%20Layout%20Analysis%20via%20Tab-Stop%20Detection.pdf)
2009,Adapting the Tesseract Open Source OCR Engine for Multilingual OCR(https://github.com/guzhenping/the-Papers-and-Data-of-Tesseract-OCR-/blob/master/Adapting%20the%20Tesseract%20Open%20Source%20OCR%20Engine%20for%20Multilingual%20OCR.pdf)
The Fourth Annual Test of OCR Accuracy[不是Ray所写](https://github.com/guzhenping/the-Papers-and-Data-of-Tesseract-OCR-/blob/master/The%20Fourth%20Annual%20Test%20of%20OCR%20Accuracy.pdf)
需要深入研究的请戳链接(https://github.com/guzhenping/the-Papers-and-Data-of-Tesseract-OCR-)。以上都是英文资料,中国人帮助中国人,所以我会把我翻译过的一部分公布出来,欢迎关注。if 没有公布,欢迎来问,前3篇论文都已经看过2、3遍了,还是知道一些东西的。
OCR概述
全称Optical Character Recognition ,中文即:光学字符识别。这是文字自动输入的一种方法,通过扫描和摄像等光学输入方式获取纸张上的文字图像信息,利用各种模式识别算法分析文字形态特征,判断出文字的标准编码,并按通用格式存储在文本文件中,从根本上改变了人们对计算机文字人工编码录入的概念。
我这就是瞎扯淡。大家自己去维基百科上看吧。
Tesserct概述
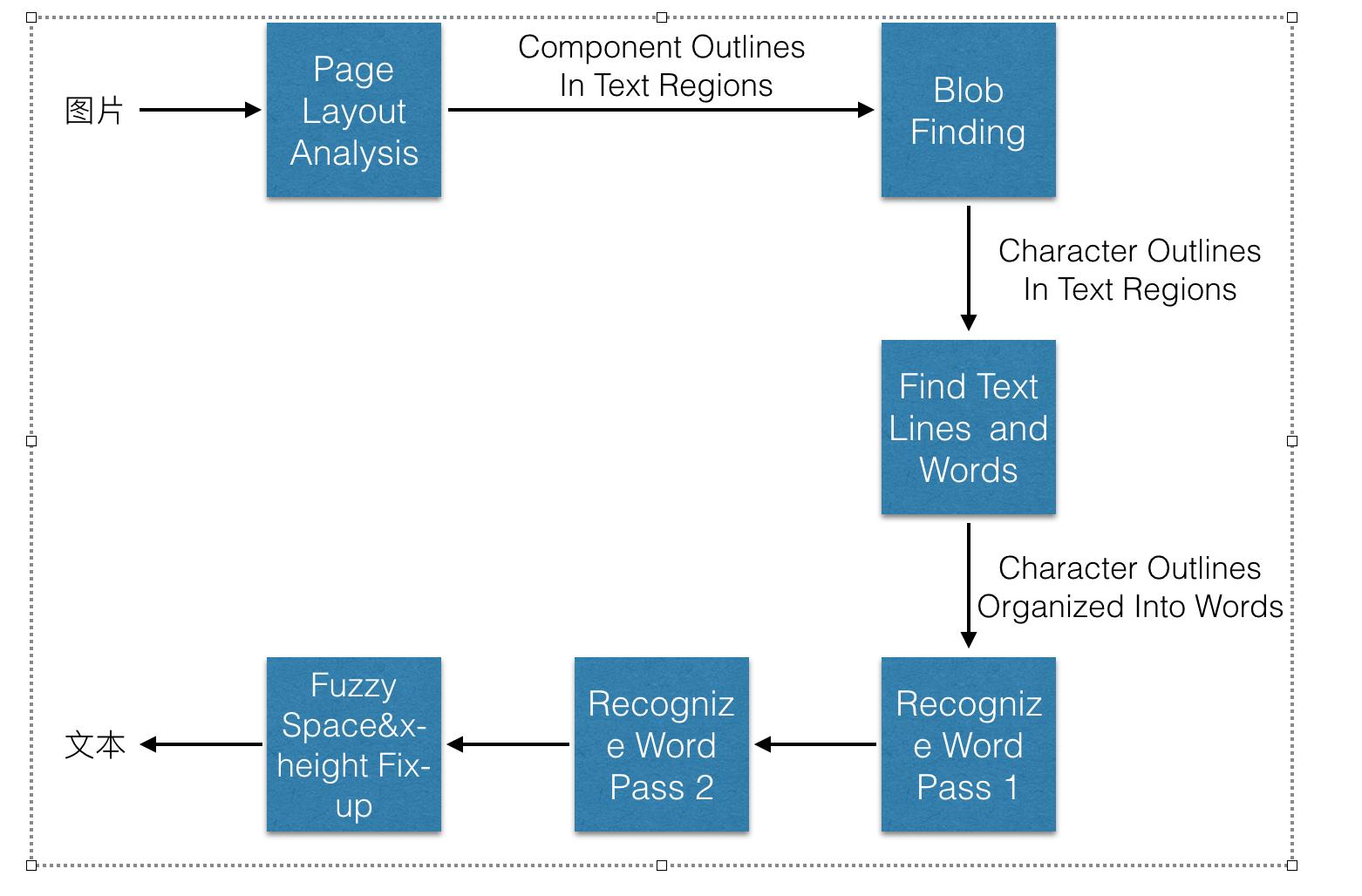
图1 识别过程图
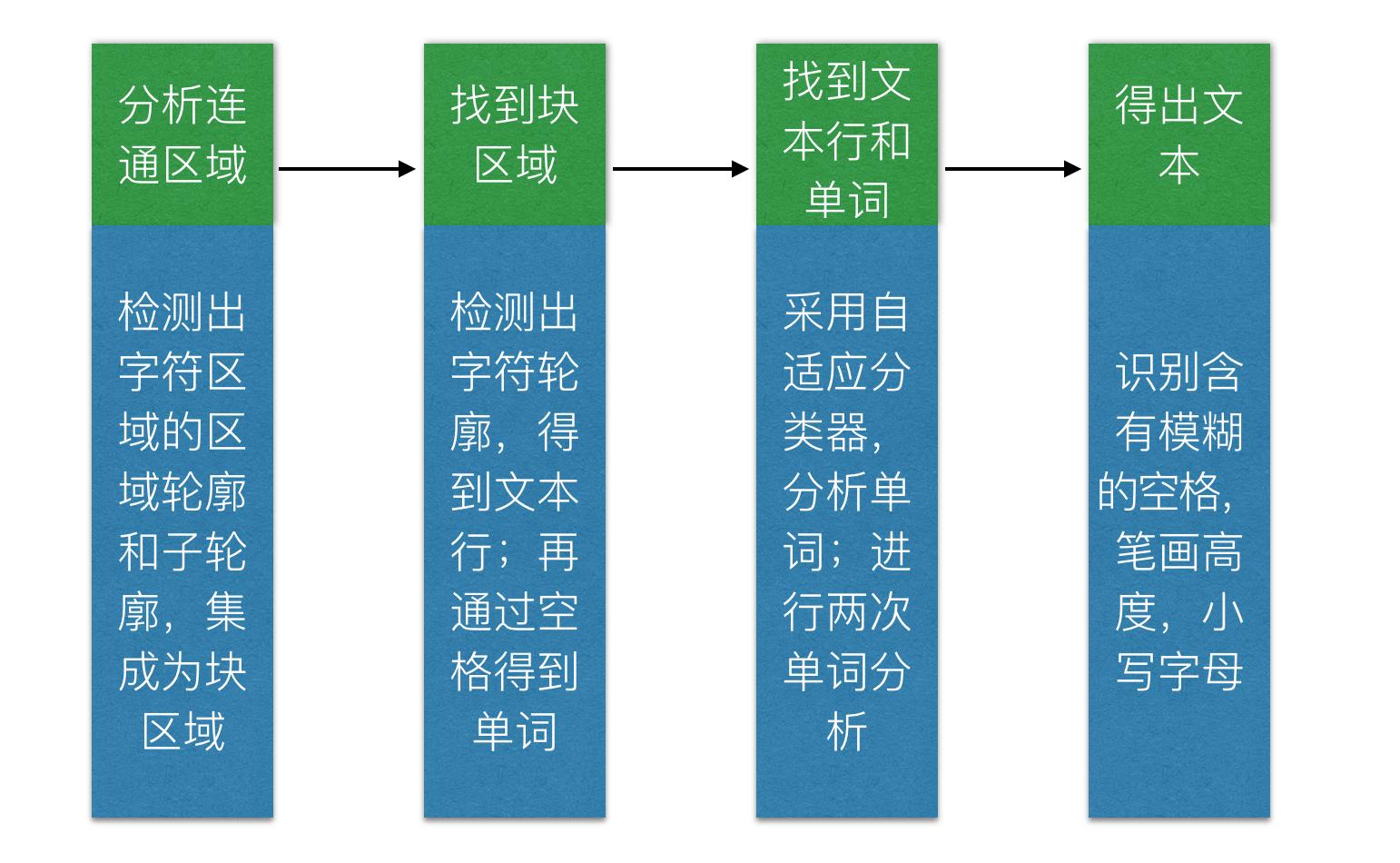
图2 识别过程图(中文版)
入门操作
开发环境(请注意你自己的):
Python2.7,用自带的IDLE即可
Ubuntu14.04 LTS
Tesseract 3.02
如果没有这些东西,试了下面的代码不成功,建议使用虚拟机(VM)来安装这些工具。
注意2点:
1 Tesseract在Github上的Python API,在你自己的电脑不一定能跑通,因为libtesseract.so.3的存储位置不同,需要自己去找自己本机的libtesseract.so.3
2 Tesseract的处理时间和图片大小有关,越大的图片用时越长,用大图片测试的童鞋请耐心等待
代码如下:
##########################################
#内容来自:谷震平的博客,http://blog.csdn.net/guzhenping
#谷震平原创,请尊重版权!
#这个是最精简的Python代码,后续会给出复杂的。
#使用说明:(1) 注意你的引擎库文件的位置,可能需要修改libname;
#(2) 我的待识别图片filename在桌面上,请注意修改,一定要把文件扩展
#名带上
##########################################
import os
import ctypes
libname = "/usr/lib/libtesseract.so.3" # tesseract引擎的动态库
lang = "eng" # 识别的语言,eng是英文,chi_sim是中文,自己选择
filename = "/home/guzhenping/Desktop/tests.jpg" # 待识别图片
# 加载动态库
tesseract = ctypes.cdll.LoadLibrary(libname)
tesseract.TessVersion.restype = ctypes.c_char_p
# 创建一个handle,请看TessBaseAPI,你就懂了为啥非要有handle
api = tesseract.TessBaseAPICreate()
# 初始化引擎
rc = tesseract.TessBaseAPIInit3(api,TESSDATA_PREFIX,lang)
# 处理待识别图片
text_out = tesseract.TessBaseAPIProcessPages(api,filename,None,0)
#转成字符串
result_text = ctypes.string_at(text_out)
print result_text # 输出结果
结语
如果希望深入研究Tesseract,欢迎交友,留言。此外,我还有印象笔记的工作记录。如果可以,欢迎交换研究资料。
这些工作还有待完善,会慢慢发布的,期待您的关注!