
一、Spark下载安装
官网地址:http://spark.apache.org/downloads.html
root@ubuntu:/usr/local# tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
root@ubuntu:/usr/local# cd spark-1.6.0-bin-hadoop2.6
二、Scala下载安装
官网地址:http://www.scala-lang.org/download/2.11.7.html
root@ubuntu:/usr/local# tar -zxvf scala-2.11.7.tgz
配置环境变量:
root@ubuntu:/usr/local# vi /etc/profile
# 添加下面语句
export SCALA_HOME=/usr/local/scala-2.11.7
export PATH=$SCALA_HOME/bin:$PATH
执行下面命令使其生效:
root@ubuntu:/usr/local# source /etc/profile
检查安装版本:
root@ubuntu:/usr/local# scala -version
Scala code runner version 2.11.7 -- Copyright 2002-2013, LAMP/EPFL
三、Spark配置
root@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6# cd conf
root@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# ls
因为目录下都是模板文件,需要从模板复制相应的配置文件,比如:
root@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# cp spark-env.sh.template spark-env.sh
根据需要可以修改配置文件内容。
四、启动Master
root@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6# sbin/start-master.sh
默认可以通过:http://localhost:8080打开Web UI。
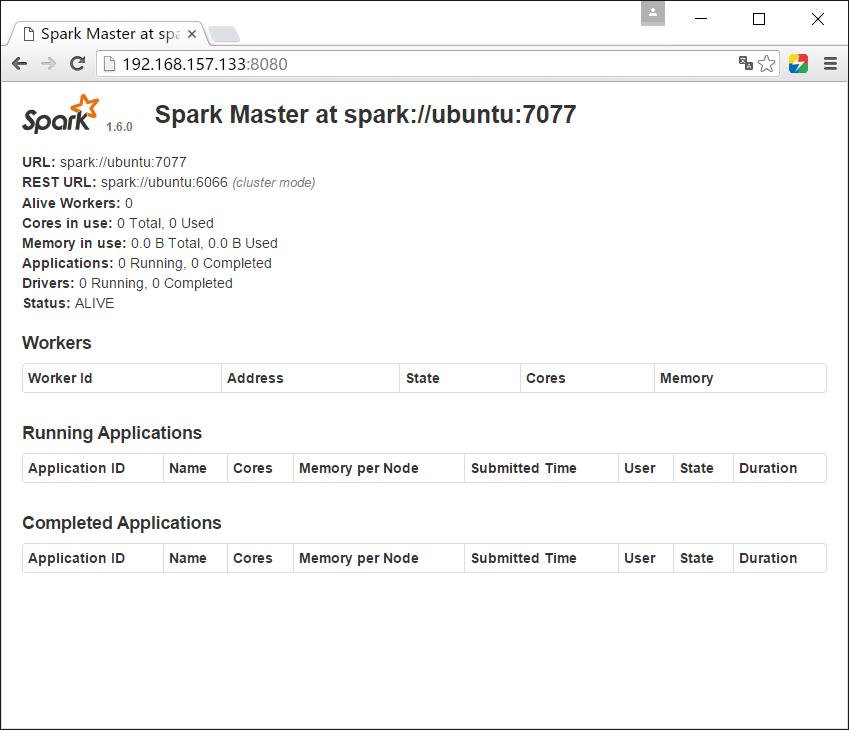
五、启动Worker
同样地,可以通过下面命令启动1个或多个workers连接到master:
./sbin/start-master.sh
root@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6# sbin/stop-slave.sh spark://ubuntu:7077
这时刷新Web界面会看到下面变化:
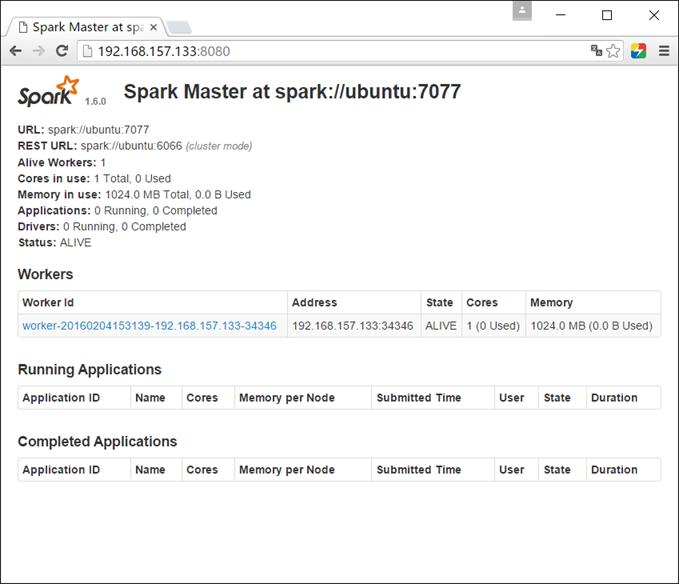
六、测试
执行下面命令,进入交互控制台:
./bin/spark-shell --master spark://IP:PORT
root@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6# bin/spark-shell --master spark://ubuntu:7077
分别输入下面语句:
scala> val textFile = sc.textFile("hdfs://hadoop:9000/user/root/input/a.txt")
scala> val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
scala> counts.collect()
可以看到输出结果:
res1: Array[(String, Int)] = Array((iceBox,1), (config,2), (text,1), (world.,1), (ice,2), (hello,2))
注意:必须保证hdfs服务已启动,并且有上面目录和文件。
执行下面程序保存结果到hdfs:
scala> counts.saveAsTextFile("hdfs://hadoop:9000/user/root/output/test")
七、停止
rain@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6$ sbin/stop-master.sh
root@ubuntu:/usr/local/spark-1.6.0-bin-hadoop2.6# sbin/stop-slave.sh spark://ubuntu:7077