
如果我们把内核中的用链表表示的数据结构画出来,那将是一盘又复杂又美味的。意大利面。就像在之前分析的VFS那样。
内核中的链表经典实现,改造一下,体会一下,玩味一下。
内核的经典双向循环链表结构跟普通教材上教的双向循环链表的实现不大一样,平常我们会把数据存储在节点中,再把节点连接起来形成链表,但是内核中的双向循环链表是用一个独立的结构体来表示的,如下:
struct list_head
{
struct list_head *prev;
struct list_head *next;
};
正如你所见,该结构体除了两个指向本身的指针之外别无他物,实际上,它们是用来被“嵌入”其他数据结构中的,以此来将各个节点串起来。
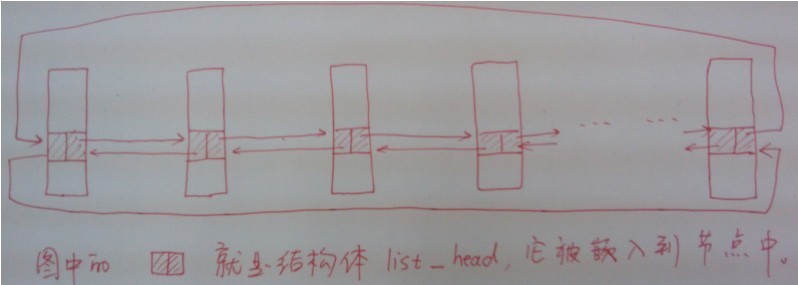
比如,我们可以定义一个这
样的结构体:
struct kool_list
{
int to;
struct list_head list;
int from;
};
这个结构体包含了 list_head,因此我们可以将多个这样的 kool_list 结构体串起来形成一个双向循环链表!下面我们就来通过对一个例子的分析看一下内核是怎么操作这种链表的(由于双向循环链表在内核中使用非常频繁,因此对链表的操作可谓是精益求精,力求高效,我们拭目以待!)
假设现在我想要创建一个包含5个 kool_list 节点的双向循环链表,节点当中的 to 字段和 from 字段随便放两个整数,创建完之后用不同的方式遍历它,然后释放它。如果是内核,她会怎么做呢?
首先不管三七二十八,我们来定义一个 kool_list 结构体,然后初始化它:
struct kool_list mylist;
INIT_LIST_HEAD(&(mylist.list));
其中宏定义如下:
#define INIT_LIST_HEAD(ptr) do { /
(ptr)->next = (ptr); /
(ptr)->prev = (ptr); /
}while(0)
这相当于把第一个节点 mylist 中的字段 list 里面的两个指针自己指向了自己,构成一个单节点的双向循环链表。
至于宏定义中的do ... while循环是为了能在宏替换语句中使用分号,使其看起来更自然。
好了,有了头结点,我们可以循环地从键盘获取5组数据,分别存储到5个节点当中,连接起来,形成一个双向循环链表:
struct kool_list *tmp;
for(i=5; i!=0; --i)
{
tmp = (strict kool_list *)malloc(sizeof(struct kool_list));
printf("enter to and from");
scanf("%d %d", &tmp->to, &tmp->from);
list_add(&(tmp->list), &(mylist.list));
}
其中,list_add() 的实现如下:
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
而 __list_add() 的实现如下:
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
分析起来很简单吧,总体来说函数 list_add(a, b) 的功能就是在b所指向的节点后面插入 a 指向的节点。
接下来呢,我们要把这个双向循环链表打印出来哦,代码如下:
list_for_each(pos, &mylist.list)
{
tmp = list_entry(pos, struct kool_list, list);
printf("to = %d from = %d/n", tmp->to, tmp->from);
}
这里又用到了两个宏,它们的定义如下:
#define list_for_each(pos, head) /
for(pos = (head)->next; pos != (head); /
pos = pos->next)
#define list_entry(ptr, type, member) /
((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member)))
其中 list_for_each() 很简单,直接进行宏替换就可以理解了,巧妙的是第二个宏定义 list_entry(),这个宏利用(type *)0 计算出了member 成员在结构体中的地址偏移量,从而得到整个节点的地址,分析如下:
首先,list_entry() 的功能是:已知指向节点中 list 成员的指针pos,得到一个指向该节点的指针tmp。
要实现这个功能,我们最直观的想法就是:用pos的值(成员list的地址)减去pos所指向的成员的结构体中的地址偏移量即可,而这个偏移量的计算就是: (unsigned long)(&((type *)0)->member),将0强制类型转换成type型指针,再取member(也就是list)的地址,显然就是member(也就是list)处于结构体的地址偏移值了,呵呵。
得到这个指针之后,我们就可以名正言顺地取到节点里面的成员了哦,因此就可以把 tmp->to 和 tmp->from 都打印出来啦!
接下来我们再介绍一个宏:
#define list_for_each_entry(pos, head, member) /
for(pos=list_entry((head)->next, typeof(*pos), member); /
&pos->member != (head); /
pos = list_entry(pos->member.next, typeof(*pos), member))
这个宏一边遍历链表,一边通过 head 指针取得其所在的节点指针 pos,因此把以上的遍历算法写成:
list_for_each_entry(tmp, &mylist.list, list)
printf("to = %d from = %d/n", tmp->to, tmp->from);
除了遍历链表,我们还需要删除释放链表占用的内存,代码如下:
list_for_each_safe(pos, q, &mylist.list)
{
tmp = list_entry(pos, struct kool_list, list);
printf("freeing item to = %d from = %d/n", tmp->to, tmp->from);
list_del(pos);
free(tmp);
}
这里用到了两个宏,实现分别如下:
#define list_for_each_safe(pos, n, head) /
for(pos = (head)->next, n = pos->next; pos != (head); /
pos = n, n = pos->next)
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = (void *) 0;
entry->prev = (void *) 0;
}
其中__list_del() 的实现如下:
static inline void list_del(struct list_head *entry)
{
next->prev = prev;
prev->next = next;
}
这个 list_for_each_safe(pos, n, head) 可以在边遍历边删除的时候发挥用武之地,神吧。但是如果你不需要删除,而仅仅需要遍历的话,那我们就上面提到的那个 list_for_each() 宏就可以咯哦!