
在linux的终端环境下, 我们经常使用curl或是wget来快速下载网页, 其实它们之间还是有很多细微区别的, 比如http 1.1的兼容问题, gzip解压缩功能等等.
下面是我在实践中遇到的wget不能自动解压的问题, 也就是wget对一个使用gzip压缩的http响应不会自动解压, 还是会返回压缩前的结果.以请求
http://hao.qq.com
网页为例, 使用命令
wget -d -O hao.qq.html "http://hao.qq.com"
我们会得到gzip压缩的文件,参看下面的截图
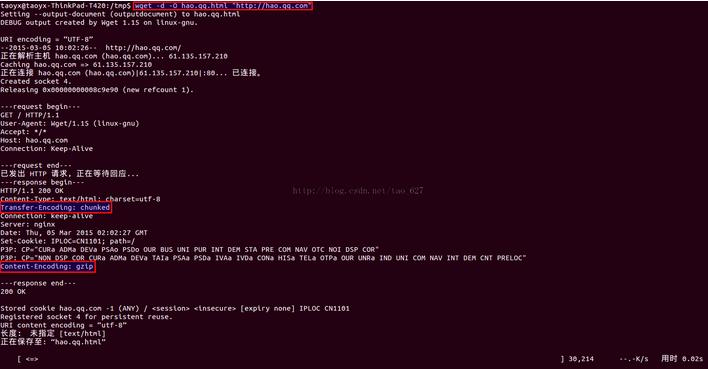
对下载后的文件格式使用file命令检测

下面我们通过gunzip来解压缩
注意gunzip只能解压后缀名为.gz的文件,不是这样的后缀名要改为这样的后缀名,比如下面
mv hao.qq.htm hao.qq.htm.gz
gunzip -c hao.qq.htm.gz > hao.qq.htm.1
我们打开解压后的文件hao.qq.htm.1, 发现它才是解压后的文件.
作为对比, 我们直接使用curl来下载,注意要使用自动解压缩选项--compressed, 否则还是不会自动解压缩
curl -v --compressed -o hao.qq.2.htm "http://hao.qq.com"
我们得到如下截图, 注意比较红色圈注
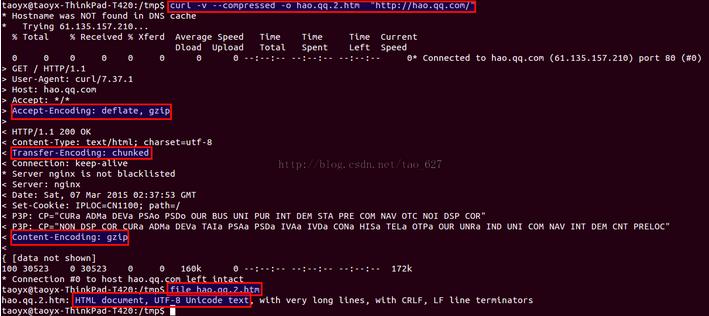
从上图易见, 它会自动解压gzip响应.这就是curl和wget的一个显著区别.
用腻了wget或curl,有什么更好的替代品吗?:http://www.linuxdiyf.com/linux/12276.html
Linux工具之curl与wget高级使用:http://www.linuxdiyf.com/linux/12126.html