
例行的Linux软中断分发机制与问题Linux的中断分为上下两半部,一般而言(事实确实也是如此),被中断的CPU执行中断处理函数,并在在本CPU上触发软中断(下半部),等硬中断处理返回后,软中断随即开中断在本CPU运行,或者wake up本CPU上的软中断内核线程来处理在硬中断中pending的软中断。
换句话说,Linux和同一个中断向量相关的中断上半部和软中断都是在同一个CPU上执行的,这个可以通过raise_softirq这个接口看出来。这种设计的逻辑是正确的,但是在某些不甚智能的硬件前提下,它工作得并不好。内核没有办法去控制软中断的分发,因此也就只能对硬中断的发射听之任之。这个分为两类情况:
1.硬件只能中断一个CPU按照上述逻辑,如果系统存在多个CPU核心,那么只能由一个CPU处理软中断了,这显然会造成系统负载在各个CPU间不均衡。
2.硬件盲目随机中断多个CPU注意”盲目“一词。这个是和主板以及总线相关的,和中断源关系并不大。因此具体中断哪个CPU和中断源的业务逻辑也无关联,比如主板和中断控制器并不是理会网卡的数据包内容,更不会根据数据包的元信息中断不同的CPU...即,中断源对中断哪个CPU这件事可以控制的东西几乎没有。为什么必须是中断源呢?因此只有它知道自己的业务逻辑,这又是一个端到端的设计方案问题。
因此,Linux关于软中断的调度,缺乏了一点可以控制的逻辑,少了一点灵活性,完全就是靠着硬件中断源中断的CPU来,而这方面,硬件中断源由于被中断控制器和总线与CPU隔离了,它们之间的配合并不好。因此,需要加一个软中断调度层来解决这个问题。
本文描述的并不是针对以上问题的一个通用的方案,因为它只是针对为网络数据包处理的,并且RPS在被google的人设计之初,其设计是高度定制化的,目的很单一,就是提高Linux服务器的性能。而我,将这个思路移植到了提高Linux路由器的性能上。
基于RPS的软中断分发优化在Linux转发优化那篇文章《Linux转发性能评估与优化(转发瓶颈分析与解决方案)》中,我尝试了网卡接收软中断的负载均衡分发,当时尝试了将该软中断再次分为上下半部:
上半部:用于skb在不同的CPU间分发。
下半部:用户skb的实际协议栈接收处理。
事实上,利用Linux 2.6.35以后加入的RPS的思想可能会有更好的做法,根本不用重新分割网络接收软中断。它基于以下的事实:
事实1:网卡很高端的情况如果网卡很高端,那么它一定支持硬件多队列特性以及多中断vector,这样的话,就可以直接绑定一个队列的中断到一个CPU核心,无需软中断重分发skb。
事实2:网卡很低档的情况如果网卡很低档,比如它不支持多队列,也不支持多个中断vector,且无法对中断进行负载均衡,那么也无需让软中断来分发,直接要驱动里面分发岂不更好(其实这样做真的不好)?事实上,即便支持单一中断vector的CPU间负载均衡,最好也要禁掉它,因为它会破坏CPU cache的亲和力。
为什么以上的两点事实不能利用中断中不能进行复杂耗时操作,不能由复杂计算。中断处理函数是设备相关的,一般不由框架来负责,而是由驱动程序自己负责。协议栈主框架只维护一个接口集,而驱动程序可以调用接口集内的API。你能保证驱动的编写人员可以正确利用RPS而不是误用它吗?
正确的做法就是将这一切机制隐藏起来,外部仅仅提供一套配置,你(驱动编写人员)可以开启它,关闭它,至于它怎么工作的,你不用关心。
因此,最终的方案还是跟我最初的一样,看来RPS也是这么个思路。修改软中断路径中NAPI poll回调!然而poll回调也是驱动维护的,因此就在数据包数据的公共路径上挂接一个HOOK,来负责RPS的处理。
为什么要禁掉低端网卡的CPU中断负载均衡答案似乎很简单,答案是:因为我们自己用软件可以做得更好!而基于简单硬件的单纯且愚蠢的盲目中断负载均衡可能会(几乎一定会)弄巧成拙!
这是为什么?因为简单低端网卡硬件不识别网络流,即它只能识别到这是一个数据包,而不能识别到数据包的元组信息。如果一个数据流的第一个数据包被分发到了CPU1,而第二个数据包分发到了CPU2,那么对于流的公共数据,比如nf_conntrack中记录的东西,CPU cache的利用率就会比较低,cache抖动会比较厉害。对于TCP流而言,可能还会因为TCP串行包并行处理的延迟不确定性导致数据包乱序。因此最直接的想法就是将属于一个流的所有数据包分发了一个CPU上。
我对原生RPS代码的修改要知道,Linux的RPS特性是google人员引入的,他们的目标在于提升服务器的处理效率。因此他们着重考虑了以下的信息:
哪个CPU在为这个数据流提供服务;
哪个CPU被接收了该流数据包的网卡所中断;
哪个CPU运行处理该流数据包的软中断。
理想情况,为了达到CPU cache的高效利用,上面的三个CPU应该是同一个CPU。而原生RPS实现就是这个目的。当然,为了这个目的,内核中不得不维护一个”流表“,里面记录了上面三类CPU信息。这个流表并不是真正的基于元组的流表,而是仅仅记录上述CPU信息的表。
而我的需求则不同,我侧重数据转发而不是本地处理。因此我的着重看的是:
哪个CPU被接收了该流数据包的网卡所中断;
哪个CPU运行处理该流数据包的软中断。
其实我并不看中哪个CPU调度发送数据包,发送线程只是从VOQ中调度一个skb,然后发送,它并不处理数据包,甚至都不会去访问数据包的内容(包括协议头),因此cache的利用率方面并不是发送线程首要考虑的。
因此相对于Linux作为服务器时关注哪个CPU为数据包所在的流提供服务,Linux作为路由器时哪个CPU数据发送逻辑可以忽略(虽然它也可以通过设置二级缓存接力[最后讲]来优化一点)。Linux作为路由器,所有的数据一定要快,一定尽可能简单,因为它没有Linux作为服务器运行时服务器处理的固有延迟-查询数据库,业务逻辑处理等,而这个服务处理的固有延迟相对网络处理处理延迟而言,要大得多,因此作为服务器而言,网络协议栈处理并不是瓶颈。服务器是什么?服务器是数据包的终点,在此,协议栈只是一个入口,一个基础设施。
在作为路由器运行时,网络协议栈处理延迟是唯一的延迟,因此要优化它!路由器是什么?路由器不是数据包的终点,路由器是数据包不得不经过,但是要尽可能快速离开的地方!
所以我并没有直接采用RPS的原生做法,而是将hash计算简化了,并且不再维护任何状态信息,只是计算一个hash:
[plain] view plaincopyprint?
target_cpu = my_hash(source_ip, destination_ip, l4proto, sport, dport) % NR_CPU;
target_cpu = my_hash(source_ip, destination_ip, l4proto, sport, dport) % NR_CPU;[my_hash只要将信息足够平均地进行散列即可!]
仅此而已。于是get_rps_cpu中就可以仅有上面的一句即可。
这里有一个复杂性要考虑,如果收到一个IP分片,且不是第一个,那么就取不到四层信息,因为可能会将它们和片头分发到不同的CPU处理,在IP层需要重组的时候,就会涉及到CPU之间的数据互访和同步问题,这个问题目前暂不考虑。
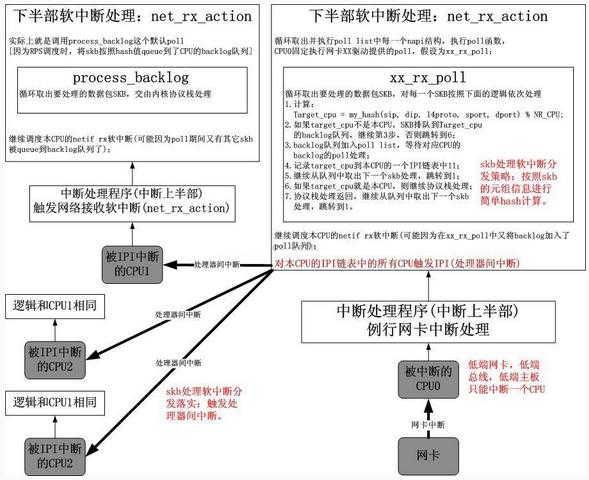
NET RX软中断负载均衡总体框架本节给出一个总体的框架,网卡很低端,假设如下:
不支持多队列;
不支持中断负载均衡;
只会中断CPU0。
它的框架如下图所示:
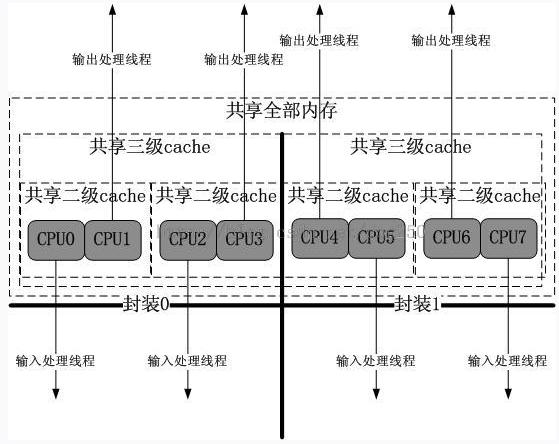
CPU亲和接力优化本节稍微提一点关于输出处理线程的事,由于输出处理线程逻辑比较简单,就是执行调度策略然后有网卡发送skb,它并不会频繁touch数据包(请注意,由于采用了VOQ,数据包在放入VOQ的时候,它的二层信息就已经封装好了,部分可以采用分散/聚集IO的方式,如果不支持,只能memcpy了...),因此CPU cache对它的意义没有对接收已经协议栈处理线程的大。然而不管怎样,它还是要touch这个skb一次的,为了发送它,并且它还要touch输入网卡或者自己的VOQ,因此CPU cache如果与之亲和,势必会更好。
为了不让流水线单独的处理过长,造成延迟增加,我倾向于将输出逻辑放在一个单独的线程中,如果CPU核心够用,我还是倾向于将其绑在一个核心上,最好不要绑在和输入处理的核心同一个上。那么绑在哪个或者哪些上好呢?
我倾向于共享二级cache或者三级cache的CPU两个核心分别负责网络接收处理和网络发送调度处理。这就形成了一种输入输出的本地接力。按照主板构造和一般的CPU核心封装,可以用下图所示的建议:
为什么我不分析代码实现第一,基于这样的事实,我并没有完全使用RPS的原生实现,而是对它进行了一些修正,我并没有进行复杂的hash运算,我放宽了一些约束,目的是使得计算更加迅速,无状态的东西根本不需要维护!
第二,我发现我逐渐看不懂我以前写的代码分析了,同时也很难看明白大批批的代码分析的书,我觉得很难找到对应的版本和补丁,但是基本思想却是完全一样的。因此我比较倾向于整理出事件被处理的流程,而不是单纯的去分析代码。
声明:本文是针对底端通用设备的最后补偿,如果有硬件结合的方案,自然要忽略本文的做法。
Linux下LVS搭建负载均衡集群:http://www.linuxdiyf.com/linux/12508.html
RHEL6平台LVS实现负载均衡Load Balancer:http://www.linuxdiyf.com/linux/11881.html
Linux服务器之LVS、Nginx和HAProxy负载均衡器对比总结:http://www.linuxdiyf.com/linux/10787.html
CentOS+Nginx一步一步开始配置负载均衡:http://www.linuxdiyf.com/linux/10205.html