
1. 启动Hadoop
进入root权限,进入Hadoop安装目录$HADOOP_HOME
执行Bin/start-all.sh
Jps查看hadoop进程
2. 启动eclipse
进入eclipse的安装目录,在root权限下运行eclipse
./eclipse& 后台运行以便进行其它操作。
3. Eclipse装Hadoop插件
Window->preference->HadoopMapReduce 设置好Hadoop的安装目录
/usr/programFiles/hadoop-1.0.1
Eclipse中本没有hadoop插件,所以要安装eclipse的hadoop插件
4. 配置Map/Reduce Locations
Windows->Show View->Map/Reduce Locations 打开Map/ReduceLocations
右键->New Hadoop Location
填入mapred-site.xml、core-site.xml中配置的地址及端口,如下所示:

5. 新建项目
File-->New-->Other-->Map/Reduce Project,项目名可以随便取如WordCount_root。
复制 hadoop安装目录/src/example/org/apache/hadoop/examples/WordCount.java到刚才新建的项目WordCount下,修改WordCount.java首行package为mypackage。
6. 在hadoop安装目录下创建文件夹:
在/usr/programFiles/hadoop-1.0.1下创建test_wordCount_0103
在test_wordCount_0103文件夹下创建file0、file1文件,分别写入一些单词。
在HDFS分布式文件系统中创建目录input:bin/hadoop fs –mkdir input
7. 将数据从Linux文件系统复制到HDFS分布式文件系统中
bin/hadoop fs –put/usr/programFiles/hadoop-1.0.1/test_wordCount_0103 input
8. Run
右键项目->Run As->Run Configurations
点Java Application,右键-->New,这时会新建一个application名为WordCount。
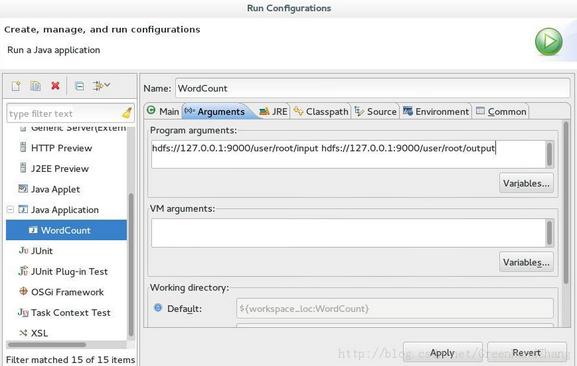
配置运行参数,点Arguments,在Program arguments中输入你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹,如下图所示。注意这里的output一定是不存在的文件,存在就会报错!
点击Run,运行程序。
9. 查看结果
bin/hadoop fs –ls output

bin/hadoop fs –cat output/part-r-00000 或者直接output/*也行

其中input的内容是:
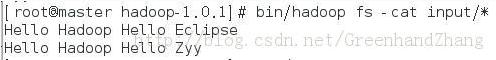
注:以上图片上传到红联Linux系统教程频道中。