
简介:网络文件系统(NFS)从 1984 年问世以来持续演变,并已成为分布式文件系统的基础。当前,NFS(通过 pNFS 扩展)通过网络对分布的文件提供可扩展的访问。探索分布式文件系背后的理念,特别是,最近 NFS 文件进展。
络文件系统 是文件系统之上的一个网络抽象,来允许远程客户端以与本地文件系统类似的方式,来通过网络进行访问。虽然 NFS 不是第一个此类系统,但是它已经发展并演变成 UNIX? 系统中最强大最广泛使用的网络文件系统。NFS 允许在多个用户之间共享公共文件系统,并提供数据集中的优势,来最小化所需的存储空间。
本文以 NFS 的简短历史开始,到它的起源,再到它如何演化。然后探索了 NFS架构以及 NFS 的走向。
NFS 的简短历史
第一个网络文件系统 — 称为 File Access Listener — 由 Digital Equipment Corporation(DEC)在 1976 年开发。Data Access Protocol(DAP)的实施,这是 DECnet 协议集的一部分。比如 TCP/IP,DEC 为其网络协议发布了协议规范,包括 DAP。
NFS 是第一个现代网络文件系统(构建于 IP 协议之上)。在 20 世纪 80 年代,它首先作为实验文件系统,由 Sun Microsystems 在内部完成开发。NFS 协议已归档为 Request for Comments(RFC)标准,并演化为大家熟知的 NFSv2。作为一个标准,由于 NFS 与其他客户端和服务器的互操作能力而发展快速。
标准持续地演化为 NFSv3,在 RFC 1813 中有定义。这一新的协议比以前的版本具有更好的可扩展性,支持大文件(超过 2GB),异步写入,以及将 TCP 作为传输协议,为文件系统在更广泛的网络中使用铺平了道路。在 2000 年,RFC 3010(由 RFC 3530 修订)将 NFS 带入企业设置。Sun 引入了具有较高安全性,带有状态协议的 NFSv4(NFS 之前的版本都是无状态的)。今天,NFS 是版本 4.1(由 RFC 5661 定义),它增加了对跨越分布式服务器的并行访问的支持(称为 pNFS extension)。
NFS 的时间表,包括记录其特性的特定 RFC ,都在图 1 中有展示。
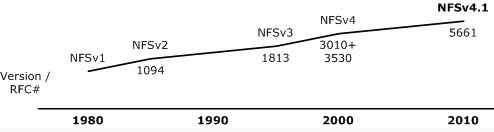
令人惊讶的是,NFS 已经历了几乎 30 年的开发。 它代表了一个非常稳定的(及可移植)网络文件系统,它可扩展、高性能、并达到企业级质量。由于网络速度的增加和延迟的降低,NFS 一直是通过网络提供文件系统服务具有吸引力的选择。甚至在本地网络设置中,虚拟化驱动存储进入网络,来支持更多的移动虚拟机。NFS 甚至支持最新的计算模型,来优化虚拟的基础设施。
NFS 架构
NFS 允许计算的客户 — 服务器模型(见图 2)。服务器实施共享文件系统,以及客户端所连接的存储。客户端实施用户接口来共享文件系统,并加载到本地文件空间当中。
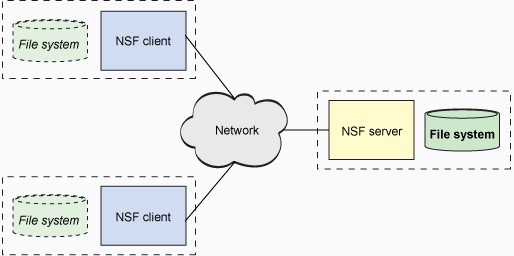
在 Linux 中,虚拟文件系统交换(VFS)提供在一个主机上支持多个并发文件系统的方法(比如 CD-ROM 上的 International Organization for Standardization [ISO] 9660,以及本地硬盘上的 ext3fs )。VFS 确定需求倾向于哪个存储,然后使用哪些文件系统来满足需求。由于这一原因,NFS 是与其他文件系统类似的可插拔文件系统。对于 NFS 来说,唯一的区别是输入/输出(I/O)需求无法在本地满足,而是需要跨越网络来完成。
一旦发现了为 NFS 指定的需求,VFS 会将其传递给内核中的 NFS 实例。 NFS 解释 I/O 请求并将其翻译为 NFS 程序(OPEN、ACCESS、CREATE、READ、CLOSE、REMOVE 等等)。这些程序,归档在特定 NFS RFC 中,指定了 NFS 协议中的行为。一旦从 I/O 请求中选择了程序,它会在远程程序调用(RPC)层中执行。正如其名称所暗示的,RPC 提供了在系统间执行程序调用的方法。它将封送 NFS 请求,并伴有参数,管理将它们发送到合适的远程对等级,然后管理并追踪响应,提供给合适的请求者。
进一步来说,RPC 包括重要的互操作层,称为外部数据表示(XDR),它确保当涉及到数据类型时,所有 NFS 参与者使用相同的语言。当给定架构执行请求时,数据类型表示可能不同于满足需求的目标主机上的数据类型。XDR 负责将类型转换为公共表示(XDR),便于所有架构能够与共享文件系统互操作。XDR 指定类型字节格式(比如 float)和类型的字节排序(比如修复可变长数组)。虽然 XDR 以其在 NFS 中的使用而闻名,当您在公共应用程序设置中处理多个架构时,它是一个有用的规范。
一旦 XDR 将数据转换为公共表示,需求就通过网络传输给出传输层协议。早期 NFS 采用 Universal Datagram Protocol(UDP),但是,今天 TCP 因为其优越的可靠性而更加通用。
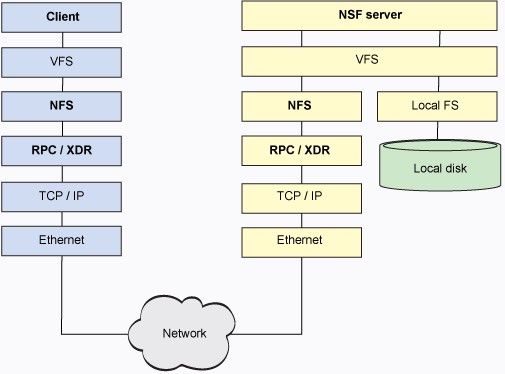
在服务器端,NFS 以相似的风格运行。需求到达网络协议栈,通过 RPC/XDR(将数据类型转换为服务器架构) 然后到达 NFS 服务器。NFS 服务器负责满足需求。需求向上提交给 NFS 守护进程,它为需求标示出目标文件系统树,并且 VFS 再次用于在本地存储中获取文件系统。整个流程在图 3 中有展示。注意,服务器中的本地文件系统是典型的 Linux 文件系统(比如 ext4fs)。因此,NFS 不是传统意义上的文件系统,而是访问远程文件系统的协议。
注:以上图片上传到红联Linux系统教程频道中。
对于高延迟网络,NFSv4 实现称为 compound procedure 的程序。这一程序从本质上允许在单个请求中嵌入多个 RPC 调用,来最小化通过网络请求的 transfer tax。它还为响应实现回调模式。
NFS 协议
从客户端的角度来说,NFS 中的第一个操作称为 mount。 Mount 代表将远程文件系统加载到本地文件系统空间中。该流程以对 mount(Linux 系统调用)的调用开始,它通过 VFS 路由到 NFS 组件。确认了加载端口号之后(通过 get_port 请求对远程服务器 RPC 调用),客户端执行 RPC mount 请求。这一请求发生在客户端和负责 mount 协议(rpc.mountd)的特定守护进程之间。这一守护进程基于服务器当前导出文件系统来检查客户端请求;如果所请求的文件系统存在,并且客户端已经访问了,一个 RPC mount 响应为文件系统建立了文件句柄。客户端这边存储具有本地加载点的远程加载信息,并建立执行 I/O 请求的能力。这一协议表示一个潜在的安全问题;因此,NFSv4 用内部 RPC 调用替换这一辅助 mount 协议,来管理加载点。
要读取一个文件,文件必须首先被打开。在 RPC 内没有 OPEN 程序;反之,客户端仅检查目录和文件是否存在于所加载的文件系统中。客户端以对目录的 GETATTR RPC 请求开始,其结果是一个具有目录属性或者目录不存在指示的响应。接下来,客户端发出 LOOKUP RPC 请求来查看所请求的文件是否存在。如果是,会为所请求的文件发出 GETATTR RPC 请求,为文件返回属性。基于以上成功的 GETATTRs 和 LOOKUPs,客户端创建文件句柄,为用户的未来需求而提供的。
利用在远程文件系统中指定的文件,客户端能够触发 READ RPC 请求。READ 包含文件句柄、状态、偏移、和读取计数。客户端采用状态来确定操作是否可执行(那就是,文件是否被锁定)。偏移指出是否开始读取,而计数指出所读取字节的数量。服务器可能返回或不返回所请求字节的数量,但是会指出在 READ RPC 回复中所返回(随着数据)字节的数量。
NFS 中的创新
NFS 的两个最新版本(4 和 4.1)对于 NFS 来说是最有趣和最重要的。让我们来看一下 NFS 创新最重要的一些方面。
在 NFSv4 之前,存在一定数量的辅助协议用于加载、锁定、和文件管理中的其他元素。NFSv4 将这一流程简化为一个协议,并将对 UDP 协议的支持作为传输协议移除。NFSv4 还集成支持 UNIX 和基于 Windows? 的文件访问语义,将本地集成 NFS 扩展到其他操作系统中。
NFSv4.1 介绍针对更高扩展性和更高性能的并行 NFS(pNFS)的概念。 要支持更高的可扩展性,NFSv4.1 具有脚本,与集群化文件系统风格类似的拆分数据/元数据架构。如 图 4 所展示的,pNFS 将生态系统拆分为三个部分:客户端、服务器和存储。您可看到存在两个路径:一个用于数据,另一个用于控制。pNFS 将数据布局与数据本身拆分,允许双路径架构。当客户想要访问文件时,服务器以布局响应。布局描述了文件到存储设备的映射。当客户端具有布局时,它能够直接访问存储,而不必通过服务器(这实现了更大的灵活性和更优的性能)。当客户端完成文件操作时,它会提交数据(变更)和布局。如果需要,服务器能够请求从客户端返回布局。
pNFS 实施多个新协议操作来支持这一行为。LayoutGet 和 LayoutReturn 分别从服务器获取发布和布局,而 LayoutCommit 将来自客户端的数据提交到存储库,以便于其他用户使用。服务器采用 LayoutRecall 从客户端回调布局。布局跨多个存储设备展开,来支持并行访问和更高的性能。
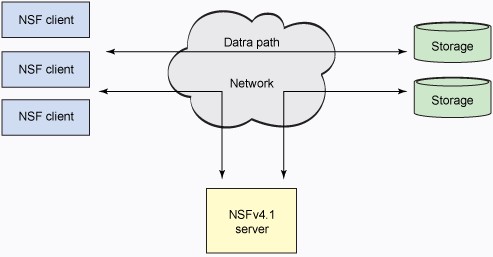
数据和元数据都存储在存储区域中。客户端可能执行直接 I/O ,给出布局的回执,而 NFSv4.1 服务器处理元数据管理和存储。虽然这一行为不一定是新的,pNFS 增加功能来支持对存储的多访问方法。当前,pNFS 支持采用基于块的协议(光纤通道),基于对象的协议,和 NFS 本身(甚至以非 pNFS 形式)。
通过 2010 年 9 月发布的对 NFSv2 的请求,继续开展 NFS 工作。其中以新的提升定位了虚拟环境中存储的变化。例如,数据复制与在虚拟机环境中非常类似(很多操作系统读取/写入和缓存相同的数据)。由于这一原因,存储系统从整体上理解复制发生在哪里是很可取的。这将在客户端保留缓存空间,并在存储端保存容量。NFSv4.2 建议用共享块来处理这一问题。因为存储系统已经开始在后端集成处理功能,所以服务器端复制被引入,当服务器可以高效地在存储后端自己解决数据复制时,就能减轻内部存储网络的负荷。其他创新出现了,包括针对 flash 存储的子文件缓存,以及针对 I/O 的客户端提示 (潜在地采用 mapadvise 作为路径)。
NFS 的替代物
虽然 NFS 是在 UNIX 和 Linux 系统中最流行的网络文件系统,但它当然不是唯一的选择。在 Windows? 系统中,ServerMessage Block [SMB](也称为 CIFS)是最广泛使用的选项(如同 Linux 支持 SMB一样,Windows 也支持 NFS)。
最新的分布式文件系统之一,在 Linux 中也支持,是 Ceph。Ceph 设计为容错的分布式文件系统,它具有 UNIX 兼容的 Portable Operating System Interface(POSIX)。您可在 参考资料 中深入了解 Ceph。
其他例子包括 OpenAFS,是 Andrew 分布式文件系统的开源版(来自 Carnegie Mellon 和 IBM),GlusterFS,关注于可扩展存储的通用分布式文件系统,以及 Lustre,关注于集群计算的大规模并行分布式文件系统。所有都是用于分布式存储的开源软件解决方案。
更进一步
NFS 持续演变,并与 Linux 的演变类似(支持低端、嵌入式、和高端性能),NFS 为客户和企业实施可扩展存储解决方案。关注 NFS 的未来可能会很有趣,但是根据历史和近期的情况看,它将会改变人们查看和使用文件存储的方法。