
如何自己的Linux系统版本是64位的同学,要自己编译Hadoop的64位库,因为官方没提供64位版本。
创建具有超级权限的hadoop用户:
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
用hadoop 登陆系统
安装ssh
sudo apt-get install ssh
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
export HADOOP\_PREFIX=/usr/local/hadoop
最后达到无密码登录
ssh localhost
修改网卡配置:
vi /etc/hosts
注释掉127.0.1.1 ubuntu
添加新的映射
(虚拟机本机IP,这里最好的设置为静态IP) master
vi /etc/hostname
中修改主机名为master
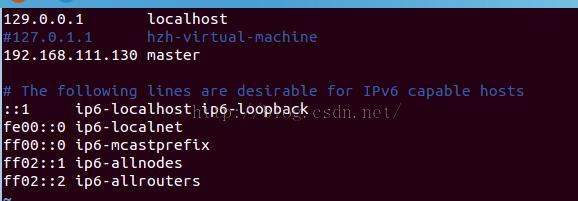
这里必须修改,否则后面会遇到连接拒绝等问题
/etc/hosts文件中的主机名和IP必须匹配。/etc/hostname中的主机名必须与实际一致。
安装rsync
sudo apt-get install rsync
安装Hadoop
解压
sudo tar xzf hadoop-2.7.1.tar.gz
copy到/usr/local/中,并命名为hadoop
sudo mv hadoop-2.7.1 /usr/local/
cd /usr/local
sudo mv hadoop-2.7.1 hadoop
修改目录主人
sudo chown hadoop:hadoop -R -f /usr/local/hadoop/
配置
sudo vi /etc/profile
添加以下命令语句:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386/
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
进入配置目录/usr/local/hadoop
修改配置文件:
etc/hadoop/hadoop-env.sh
查看Java安装目录
update-alternatives --config java
添加JAVA_HOME、HADOOP_COMMON_HOME
export JAVA_HOME="/usr/lib/jvm/java-7-openjdk-i386"
export HADOOP_COMMON_HOME="/usr/local/hadoop/"
配置环境变量
sudo vi /etc/environment
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/local/hadoop/bin:/usr/local/hadoop/sbin"
生效
source /etc/environment
修改配置文件:
修改文件etc/hadoop/core-site.xml
添加如下内容:
含义:接收Client连接的RPC端口,用于获取文件系统metadata信息。在/home/hadoop/目录下创建hadoop_tmp用于保存临时数据,注意用户权限为hadoop
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
修改etc/hadoop/hdfs-site.xml:
添加如下内容:
含义:备份只有一份
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
</configuration>
伪分布模式:
格式化namenode
bin/hdfs namenode -format
启动集群:
start-dfs.sh
验证:
http://localhost:50070/
配置Yarn:
修改配置文件mapred-site.xml
编辑文件etc/hadoop/mapred-site.xml,添加下面内容由于etc/hadoop中没有mapred-site.xml,所以对mapred-queues.xml.template复制一份
cp mapred-site.xml.template mapred-site.xml
然后编辑文件mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
然后编辑文件yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>127.0.0.1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>127.0.0.1:8031</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
启动Yarn
start-yarn.sh
如果没有配置环境变量,则需要进入hadoop_home,执行下面命令
sbin/start-yarn.sh
验证:
http://localhost:8088/
启动job
mr-jobhistory-daemon.sh start historyserver
测试
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hadoop
hadoop fs -mkdir /user/hadoop /input
hadoop fs -ls /user/hadoop /input
hadoop fs -put etc/hadoop/*.xml /user/hadoop/input
hadoop fs -lsr /user/hadoop /input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+'
ubuntu安装hadoop_cdh5.4.1步骤:http://www.linuxdiyf.com/linux/13862.html
Ubuntu15中安装hadoop2.7单机模式:http://www.linuxdiyf.com/linux/13027.html
ubuntu15.04安裝hadoop2.6.0及eclipse开发环境配置:http://www.linuxdiyf.com/linux/12474.html
Ubuntu15.04单机/伪分布式安装配置Hadoop与Hive试验机:http://www.linuxdiyf.com/linux/11858.html
Ubuntu下安装Hadoop(单机版):http://www.linuxdiyf.com/linux/11372.html