
1、集群介绍
1.1 Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框 架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任 务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交 时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
1.2 环境说明
测试环境一共3台:
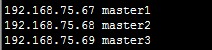
192.168.75.67 master1
192.168.75.68 master2
192.168.75.69 master3
三台机器参数:4VCPU 8GB 内存 200G硬盘
linux 操作系统版本:

1.3 网络配置
Hadoop集群要按照1.2小节表格所示进行配置。下面的例子我们将以Master机器为例,即主机名为"master1",IP为"192.168.75.67"进行一些主机名配置的相关操作。其他的Slave机器以此为依据进行修改。
修改主机名

本例子将主机名定位master1

配置hosts文件(必须)
"/etc/hosts"这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName和IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名(或域名)对应的IP地址。
进行连接测试:

master3的连接测试与上述master2的测试一致。
2、SSH无密码验证配置
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用 无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到 NameNode。
2.1 安装和启动SSH协议
安装ssh、rsync。
安装SSH协议
apt-get install ssh
apt-get install rsync
(rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件);确保所有的服务器都安装,上面命令执行完毕,各台机器之间可以通过密码验证相互登陆。
2.2 配置Master无密码登录所有Salve
1)SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过 SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用 私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密 码。重要过程是将客户端Master复制到Slave上。
2)Master机器上生成密码对

ssh-keygen -t rsa -P ' ' -f ~/.ssh/id_rsa
这条命令是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在"~/.ssh"目录下。接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。

验证是否成功。
ssh localhost
3) 设置SSH配置
把公钥复制所有的Slave机器上。使用下面的命令格式进行复制公钥:scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/
例如:

这里要把公钥复制到所有的slave机器上(本例子就是master2、master3)
2)追加到授权文件"authorized_keys"
到目前为止Master.Hadoop的公钥也有了,文件夹".ssh"也有了,且权限也修改了。这一步就是把master1的公钥追加到master2的授权文件"authorized_keys"中去。使用下面命令进行追加并修改"authorized_keys"文件权限:

5)在master1使用SSH无密码登录master2
3.1 安装hadoop
下载并且解压hadoop压缩包(本文用到的hadoop版本是hadoop-1.2.1),下载后进行解压,解压的命令是:
tar -zvxf hadoop-1.2.1.tar.gz
Hadoop的安装路径添加到"/etc/profile"中

运行source /etc/profile
3.2 配置hadoop
1) 配置hadoop-env.sh

Hadoop配置文件在conf目录下,之前的版本的配置文件主要是Hadoop-default.xml和Hadoop-site.xml。由于 Hadoop发展迅速,代码量急剧增加,代码开发分为了core,hdfs和map/reduce三部分,配置文件也被分成了三个core- site.xml、hdfs-site.xml、mapred-site.xml。core-site.xml和hdfs-site.xml是站在 HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
2)配置core-site.xml文件
首先在hadoop安装目录下创建tmp文件夹

修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/gy/hadoop-1.2.1/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master1:9000</value>
</property>
</configuration>
3)配置hdfs-site.xml文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
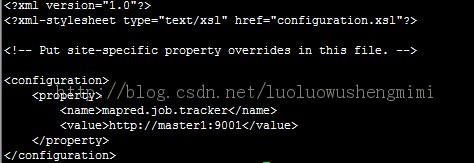
4)配置mapred-site.xml文件
5)配置masters文件

将每台hadoop机器上的masters文件内容填入主节点名称
6)配置slaves文件

值得说明和注意的是:一定一定要把每台机器上的配置都是一样的,意思是说上述的master1 master2 master3 的core-site.xml 、hdfs-site.xml、mapred-site.xml必须是一样。
4. 启动和验证
1)格式化HDFS文件系统

2)启动Hadoop
关闭防火墙

启动hadoop
调用命令:start-all.sh

检查一下是否安装正确
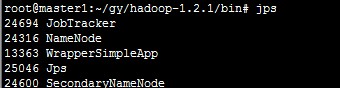
注:以上图片上传到红联Linux系统教程频道中。
主节点启动了Namenode和JobTracker,说明安装正确了,大功告成!